1. Tổng quan
Trong hệ thống Linux, các tiến trình (process) và luồng (thread) có thể ở nhiều trạng thái khác nhau trong quá trình thực thi. Những trạng thái này được phản ánh qua các công cụ như top, ps, htop… Tuy nhiên, không phải ai cũng hiểu rõ từng trạng thái có ý nghĩa gì và quan trọng hơn là chúng liên hệ thế nào với hiệu năng hệ thống, đặc biệt trong các sự cố khó phát hiện như “CPU pressure feedback loop”.
Bài viết này sẽ giúp bạn:
- Hiểu rõ các trạng thái như
R,S,D,I,Z,T,X,K… - Nhận biết từng trạng thái ứng với giai đoạn nào trong pipeline xử lý
- Phân tích một lỗi điển hình về CPU pressure gây treo Ceph OSD node mà dashboard monitoring không thể hiện rõ ràng
2. Các trạng thái process trong Linux
| Ký hiệu | Tên gọi | Ý nghĩa |
|---|---|---|
R | Running | Đang được cấp CPU và thực thi trên core |
S | Sleeping | Đang chờ một sự kiện có thể đánh thức được (I/O, socket…) |
D | Uninterruptible sleep | Chờ I/O hoặc resource, không thể bị đánh thức tạm thời (thường là disk) |
I | Idle | Chỉ có ở thread kernel: không có việc làm, rảnh hoàn toàn |
Z | Zombie | Tiến trình đã kết thúc nhưng chưa được parent thu dọn (reap) |
T | Stopped | Bị dừng tạm thời (thường do signal hoặc debug) |
X | Dead | Đã chết (hiếm thấy) |
K | Wakekill | Bị kill trong khi đang chờ uninterruptible sleep (hiếm) |
Các trạng thái phổ biến nhất trong vận hành Ceph OSD là R, S, D và đôi khi I nếu bạn theo dõi thread kernel.
3. Liên hệ các trạng thái với tầng xử lý
Dưới đây là sơ đồ logic đơn giản hóa của pipeline xử lý một request từ client tới disk qua Ceph:
Client → NIC → IRQ (HardIRQ)
↓
SoftIRQ (NET_RX)
↓
Socket Buffer / Backlog
↓
Ceph OSD (User Space Thread)
↓
BlueStore → Disk I/O- SoftIRQ: không phải là process, nhưng chiếm CPU → không hiển thị như
R/Strongtop, nhưng ảnh hưởng tới các thread khác. - Ceph OSD thread:
R: đang được chạyS: đang chờ I/O hoặc lockD: chờ diskRnhưng không tăng: đang “Waiting CPU”, xếp hàng nhưng chưa có CPU để chạy
4. Mối liên hệ giữa trạng thái R/S/D và dashboard Running / Waiting
Biểu đồ như “Process Schedule Stats: Running / Waiting” trong Grafana không phản ánh được SoftIRQ nhưng có thể cho bạn thấy số thread đang xếp hàng chờ CPU.
Nhưng nó là chìa khóa quan trọng để hiểu nguyên nhân tắc nghẽn của node Ceph này. Mình sẽ phân tích kỹ bên dưới:
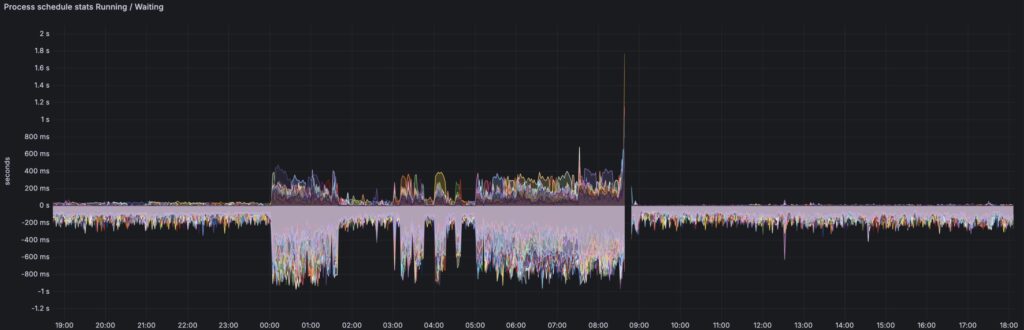
- Trạng thái
Rnhưng không thấy tăng: process đang “chờ CPU” → có trong run queue nhưng không được cấp CPU - Trạng thái
Scao: app đang chờ socket, disk, memory hoặc lock nội bộ - Trạng thái
D: chờ I/O sâu → thường do disk hoặc driver - Trạng thái
I: kernel thread rảnh rỗi
Rút ra điều gì từ biểu đồ?
Kết luận 1: Node này bị nghẽn CPU thực sự trong khoảng thời gian đó
- Không hẳn là CPU usage cao, mà là:
- Thread Ceph hoặc hệ thống xếp hàng quá nhiều, đợi được chạy
- Scheduling latency cao → Ceph-osd xử lý chậm, gây backlog
Kết luận 2: Nghẽn này phù hợp với các triệu chứng mô tả ở trên:
- Ghi disk bị giảm
- Latency tăng cao
- Client vẫn gửi đều → SoftIRQ không giảm
- Reboot xong thì hết lỗi
- Cho thấy lỗi có thể là:
- Memory fragmentation
- Ceph thread bị stuck ở trạng thái “runnable” mà không được CPU
- Ksoftirqd hoặc các thread hệ thống bị starve (chờ mãi không đến lượt)
- Kernel bug / bug Ceph gây leak thread, lock
- Như vậy:
- Biểu đồ này cực kỳ quan trọng: Nó giúp bạn xác nhận là node nghẽn do cạnh tranh CPU, chứ không phải disk hay network.
- Dữ liệu “âm sâu” cho thấy thread đợi được xử lý, nhưng CPU không đủ hoặc bị chiếm dụng bất thường.
- Nếu sau reboot hết lỗi → nghi ngờ ceph-osd leak thread, hoặc bug kernel/OS gây mất cân bằng CPU scheduling.
5. Phân tích một lỗi dạng CPU pressure feedback loop
Giai đoạn khởi phát:
- Ceph OSD đột ngột xử lý một batch object lớn
- Có thể bị lock hoặc memory pressure
- Ceph chưa xử lý xong packet đầu tiên → chưa đọc tiếp socket buffer
Giai đoạn kế tiếp:
- Client vẫn gửi request đều → gói tin tiếp tục đến
- SoftIRQ được đánh thức để xử lý → nhưng socket buffer backlog bị đầy
- Ceph chưa đọc xong → backlog không thoát kịp
- SoftIRQ tiếp tục bị gọi lại để xử lý → CPU SoftIRQ tăng cao
Giai đoạn mất kiểm soát:
- SoftIRQ chiếm nhiều core → Ceph OSD không còn CPU để xử lý tiếp
- Ceph chuyển sang trạng thái
Rnhưng không được cấp CPU (Waiting cao) - Các thread runnable bị “kẹt” vì CPU đã bị SoftIRQ chiếm dụng
- Vòng lặp này kéo dài cho đến khi reboot node mới giải thoát CPU và reset backlog
6. Lời khuyên
- Luôn theo dõi cả
SoftIRQ, không chỉUser Spacekhi phân tích CPU - Dùng
top -H,ps -eLo, hoặcperfđể bắt threadRnhưng không chạy - Kiểm tra
/proc/net/softnet_stat,ss -lntđể đo backlog socket - Tối ưu:
- Pin CPU riêng cho SoftIRQ và Ceph
- Tăng
rmem_max,tcp_rmemnếu cần - Upgrade kernel/Ceph nếu bản cũ
7. Kết luận
Hiểu rõ từng trạng thái process là chìa khóa để phân tích hiệu năng hệ thống, nhất là trong các sự cố khó phát hiện như CPU pressure feedback loop. Khi SoftIRQ tăng cao, đó không phải là nguyên nhân gốc mà là dấu hiệu của backlog đang bị nghẽn phía sau. Một đợt spike nhẹ từ User Space hoặc client request cũng có thể tạo ra vòng lặp bất tận khiến hệ thống bị tê liệt nếu không được giới hạn và tách biệt tài nguyên phù hợp.
Hiểu rõ R, S, D không chỉ giúp bạn đọc đúng dashboard, mà còn chẩn đoán nhanh hơn trong môi trường production Ceph hay hệ thống IO-intensive khác.
