1. Tổng quan
Trong vận hành hệ thống Ceph OSD sử dụng NVMe và hạ tầng mạng tốc độ cao (100G), hiện tượng CPU SoftIRQ tăng cao bất thường có thể khiến node bị treo hoặc giảm mạnh hiệu năng, dù IOPS từ client vẫn đều đặn và disk không có lỗi vật lý.
Bài viết này phân tích chi tiết nguyên nhân sâu xa đằng sau hiện tượng đó, từ các tầng xử lý như Hard IRQ → SoftIRQ → Socket Buffer → User Space → Disk, cho đến tác động dây chuyền khi Ceph OSD xử lý không kịp. Qua đó giúp sysadmin hiểu rõ hơn về vòng lặp bottleneck giữa SoftIRQ và User Space, nguyên nhân khiến CPU bị chiếm hết và giải pháp thực tiễn để xử lý hoặc phòng tránh.
Bài này cũng giúp bạn phân biệt rõ ba nguồn tiêu thụ chính của CPU khi vận hành Ceph OSD, đặc biệt BlueStore trên Linux. Từ đó bạn sẽ biết tại sao có lúc CPU softirq cao đột biến dù ceph-osd không chiếm nhiều CPU, hoặc chỗ nào trong pipeline OSD đốt CPU và cách đọc số liệu để tối ưu.
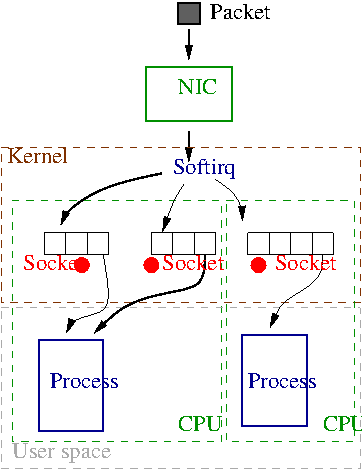
2. Luồng tiếp nhận và xử lý gói tin.
2.1. Tóm tắt về quá quy nhận gói tin.
Gói tin đến NIC:
- NIC (Network Interface Card) nhận gói tin vật lý từ dây cáp (Ethernet, Wi-Fi, v.v.)
- Khi nhận xong gói → NIC phát sinh một hành động ngắt (Hard IRQ) gửi đến CPU
- IRQ handler sẽ được kích hoạt
IRQ handler gọi vào NAPI:
- NAPI chạy trong IRQ context sẽ:
- Ghi nhận là “có hàng tới”
- Tắt IRQ để tránh “bão xử lý hành động ngắt liên tục”
- Lên lịch SoftIRQ để xử lý sau
→ Tại thời điểm này, gói tin vẫn nằm trong bộ đệm của NIC (hardware ring buffer), chưa được xử lý gì cả!
SoftIRQ (NET_RX) xử lý lần lượt:
- Khi CPU rảnh, SoftIRQ (dưới quyền của NAPI) sẽ:
- Gọi
poll()function của driver - Lấy từng gói tin từ NIC buffer lên (thường qua DMA) để xử lý:
- Copy vào bộ đệm kernel
- Gửi lên ngăn TCP/IP Stack
- Giao tiếp với socket ứng dụng…
- Gọi
Tổng kết flow:
| Giai đoạn | Mô tả |
|---|---|
| 1. NIC nhận gói | Dữ liệu đến card mạng |
| 2. Gửi IRQ | Gửi tín hiệu tới CPU: “Có gói!” |
| 3. NAPI xử lý IRQ | Tắt IRQ, đặt SoftIRQ để xử lý sau |
| 4. SoftIRQ chạy poll() | Lấy gói tin từ NIC → đẩy vào TCP/IP stack |
2.2. IRQ là gì?
IRQ chia thành 2 loại chính đó là Hard IRQ & SoftIRQ và cả hai đều thuộc về Kernel space. Dưới đây là bảng thể hiện vị trí của chúng.
| Loại IRQ | Tên đầy đủ | Vị trí xử lý | Vai trò chính |
|---|---|---|---|
| Hard IRQ | Hardware Interrupt | Kernel space | Xử lý ngắt phần cứng ngay lập tức |
| SoftIRQ | Software Interrupt | Kernel space | Xử lý chính, thực hiện sau Hard IRQ |
Hard IRQ (Hardware Interrupt Handler) – Nó như người điểm danh gói đến, nó nằm hoàn toàn trong kernel space
- CPU sẽ nhận tín hiệu từ thiết bị phần cứng (keyboard, NIC, disk, …) .
- Hard IRQ handler được gọi → process này rất nhẹ. Ví dụ gọi
napi_schedule()rồi thoát ra nhanh. - Việc của nó là chỉ gọi
napi_schedule()để báo với kernel: “Có dữ liệu đó, xử lý tiếp nha!” - Lúc này, dữ liệu vẫn nằm trong buffer của NIC, chưa ai đọc ra.
SoftIRQ (Software Interrupt) – Người xử lý chính của tầng network, nó cũng nằm hoàn toàn trong kernel space
- Là một cơ chế trong kernel để thực hiện công việc nặng hơn, sau khi Hard IRQ kết thúc.
- SoftIRQ cũng chạy trong kernel space, nhưng:
- Được gọi bởi kernel scheduler
- Có thể xử lý nhiều công việc dạng batch
- Không bị giới hạn quá nghiêm ngặt như Hard IRQ
NET_RX_SOFTIRQchạy → gọipoll()trong driver → đọc gói ra từ NIC.- Gói này sau đó đi qua các tầng trong network stack của kernel:
- IP layer
- TCP layer
- Lúc này kernel mới xác định gói này thuộc kết nối socket nào và đưa vào socket receive queue (sk_buff) của Ceph-osd daemon (user space).
Mối quan hệ giữa Hard IRQ và SoftIRQ
+-----------+ +------------------------+ +-----------------------+
| Thiết bị | -----> | Hard IRQ (IRQ handler) | -----> | SoftIRQ (e.g. NET_RX) |
+-----------+ +------------------------+ +-----------------------+
| |
| napi_schedule() |
v v
Chuyển công việc Xử lý phần còn lại
sang SoftIRQ (ví dụ: nhận gói tin)Ngoài SoftIRQ, Linux còn có thêm 2 cơ chế tương tự để trì hoãn xử lý tương tự như dưới.
| Cơ chế | Mục đích chính |
|---|---|
| SoftIRQ | Xử lý nhanh, quy mô lớn (network, block IO…) |
| Tasklet | Trừu tượng hóa từ SoftIRQ, đơn giản hơn |
| Workqueue | Cho phép xử lý ngắt trong ngữ cảnh process (có thể sleep) |
2.3. NAPI là gì?
NAPI là một cơ chế để driver liên kết 2 tầng Hard IRQ và SoftIRQ lại.
Cho phép Hard IRQ (sử dụng IRQ handler) nhẹ nhàng chuyển công việc xuống tầng SoftIRQ.
Cho phép xử lý gói tin linh hoạt (polling) và tránh Interrupt Storm (bão ngắt). Tức là khi thiết bị phần cứng (như card mạng) nhận được quá nhiều gói tin liên tục, nó sẽ liên tục gửi Interrupt Request (IRQ) đến CPU. CPU đang xử lý một tác vụ nào đó (ví dụ chạy app), thì sẽ liên tục bị ngắt để chạy các hàm xử lý IRQ. Nếu IRQ xảy ra quá thường xuyên, CPU không còn đủ thời gian cho các tác vụ khác → gây ra hiện tượng bão ngắt, làm hệ thống chậm hoặc treo.
NAPI như “người điều phối” – thấy Hard IRQ báo có gói đến thì bảo “OK, tao lo, đừng làm nữa”, rồi đưa việc xuống SoftIRQ xử lý từ từ cho ổn thỏa, theo batch, không ai bị nghẽn.
Kiểu như NAPI nói "Tao nhận được rồi, chưa xử lý ngay, đợi SoftIRQ xử lý xong thì tao sẽ đưa danh sách gói cho nó xử lý"
Card mạng gửi IRQ đến CPU:
Ê CPU! Có gói tin đến rồi nè!
NAPI (trong driver) nhảy vào xử lý IRQ đầu tiên và nói:
OK, tao biết rồi, không cần báo nữa. Tao sẽ tắt IRQ, đừng spam nữa!
NAPI chưa xử lý gì ngay, mà đẩy công việc vào queue SoftIRQ (NET_RX):
Khi CPU rảnh thì SoftIRQ sẽ xử lý danh sách gói tin tao đang có nhé!
Sau đó, SoftIRQ được lên lịch (ví dụ khi kernel thoát khỏi ngữ cảnh ngắt), nó sẽ:
- Gọi lại vào NAPI →
poll()function. - NAPI sẽ xử lý nhiều gói tin trong một lần (
quotagói/lần), để tối ưu hiệu năng.
Lưu ý quan trọng trong các card mạng mới dùng các driver mới ví dụ Intel e1000e, ixgbe, i40e, virtio-net,… nó dùng NAPI thì nó sẽ KHÔNG chuyển vào softnet_data.backlog khi hết budget/time. Thay vào đó, kernel chỉ đánh dấu lại NAPI và ksoftirqd/N sẽ tiếp tục gọi lại poll() để xử lý tiếp.
Cơ chế driver dùng NAPI và không dùng NAPI có thể tồn tại song song trong hệ thống, Nhưng:
- Mỗi driver cụ thể chỉ chọn một trong hai: hoặc có NAPI hoặc không.
- Còn toàn hệ thống thì có thể có cả hai loại driver cùng lúc, nếu có nhiều thiết bị khác nhau.
Driver dùng NAPI (hiện đại, phổ biến) hầu hết các driver mạng hiện nay (Intel e1000e, ixgbe, i40e, virtio-net, v.v.) đều dùng NAPI.
- Cơ chế:
- Xử lý IRQ → dùng
napi_schedule() - Gói tin được poll từ NIC qua
napi->poll() - Không đẩy vào
softnet_data.backlog
- Xử lý IRQ → dùng
→ Nhanh hơn, hiệu quả hơn, ít dùng CPU và RAM hơn
Driver không dùng NAPI (cũ hơn)
- Vẫn tồn tại trong hệ thống — ví dụ:
- Một số driver Wi-Fi đời cũ
- Một số virtual NIC hoặc thiết bị mạng đặc biệt
- Cơ chế:
- IRQ xảy ra → driver gọi
netif_rx(skb) - Kernel đẩy
skbvàosoftnet_data.backlog - SoftIRQ hoặc
ksoftirqdsẽ xử lýprocess_backlog()
- IRQ xảy ra → driver gọi
→ Đơn giản hơn, nhưng tốn tài nguyên và không scale tốt
Cách kiểm tra driver có dùng NAPI không?
ethtool -S eth0 | grep -i napiHoặc:
cat /sys/class/net/eth0/gro_flush_timeoutNếu có output → driver hỗ trợ NAPI hoặc GRO.
Hãy note lại nhé.
| Câu hỏi | Trả lời ngắn gọn |
|---|---|
| Một driver có thể dùng cả 2 cơ chế? | ❌ Không — mỗi driver chỉ dùng một loại |
| Một hệ thống có cả 2 cơ chế cùng lúc? | ✅ Có thể — nếu có nhiều loại driver |
| Kernel có hỗ trợ cả hai không? | ✅ Có — hoàn toàn tương thích song song |
2.4. Khái niệm về SKB và GRO trong trong Linux networking.
skblà như một cái hộp chứa mọi thông tin về một gói tin trong kernel.GROlà kỹ thuật để đóng gói các hộp skb lại → giúp giảm số hộp phải mở → hệ thống network chạy nhanh hơn.
2.4.1. SKB
SKB (struct sk_buff) và GRO (Generic Receive Offload) đóng vai trò cực kỳ quan trọng trong việc xử lý network packet một cách hiệu quả trong kernel.
SKB– Socket Buffer là cấu trúc dữ liệu trung tâm trong Linux kernel dùng để đại diện cho một network packet đang được xử lý (cả vào lẫn ra) được định nghĩa làstruct sk_buff. Mộtskbchứa rất nhiều thông tin về gói tin:- Con trỏ đến payload (dữ liệu chính)
- Header của Ethernet / IP / TCP / UDP
- Metadata: timestamp, mark, QoS, v.v.
- Liên kết với socket ứng dụng (nếu có)
- Cờ trạng thái, thông tin định tuyến, checksum…
→ Mỗi gói tin vào/ra đều được “gói” trong 1 skb.
2.4.2. GRO
GRO là một kỹ thuật tối ưu trong kernel nhằm gộp nhiều gói tin nhỏ (thường là TCP) lại thành một gói lớn hơn, trước khi tạo skb và xử lý tiếp. Mục tiêu để giảm số lượng SKB phải tạo và xử lý, từ đó giảm CPU usage và tăng throughput.
GRO hoạt động như thế nào?
- NIC nhận được nhiều gói tin liên tiếp, có cùng:
- Source/Destination IP
- Port
- TCP flags (không có FIN, RST…)
- Nếu GRO được bật:
- Các gói sẽ được “merge” lại thành một
super-packet
- Các gói sẽ được “merge” lại thành một
- Sau đó kernel mới tạo
skbcho super-packet đó
- Tức là:
- Nếu không có GRO → 5 gói → 5 SKB
- Và khi có GRO → 5 gói → 1 SKB
GRO có thể chạy ở:
- NIC hardware (nếu card hỗ trợ)
- Driver layer
- Kernel software (generic-GRO)
2.4.3. So sánh nhanh SKB và GRO
| Thuộc tính | SKB | GRO |
|---|---|---|
| Là gì? | Cấu trúc dữ liệu đại diện gói | Kỹ thuật tối ưu để gộp nhiều gói |
| Cấp độ | Data structure (ở mọi tầng) | Network driver / kernel nhận gói |
| Mục đích chính | Đại diện cho network packet | Giảm số lượng SKB + giảm load CPU |
| Khi xuất hiện | Mỗi gói luôn có SKB | Khi nhận nhiều gói TCP liên tiếp |
Dưới đây là hai sơ đồ nhẹ nhàng giúp bạn hiểu rõ về chúng
Sơ đồ luồng xử lý SKB trong kernel từ lúc gói tin đến NIC → user-space
+------------+
| NIC | ← (gói tin đến)
+------------+
↓
+---------------------+
| Driver (NAPI) | ← Gọi napi->poll()
+---------------------+
↓
+---------------------+
| Create SKB | ← struct sk_buff
| skb = netdev_alloc_skb() |
+---------------------+
↓
+---------------------+
| TCP/IP Stack |
| IP → TCP/UDP parse |
+---------------------+
↓
+---------------------+
| Find socket |
| Gán SKB vào socket |
+---------------------+
↓
+---------------------+
| User-space App | ← `recv()`
+---------------------+→ Mỗi gói tin đều tạo một SKB → xử lý riêng biệt.
Sơ đồ GRO – Gộp nhiều gói thành một SKB
Trường hợp KHÔNG có GRO:
--------------------------
NIC nhận nhiều gói liên tục:
[pkt1] [pkt2] [pkt3] [pkt4] [pkt5]
↓ ↓ ↓ ↓ ↓
Create SKB x5 → xử lý x5 lần
Trường hợp CÓ GRO:
--------------------------
NIC nhận gói:
[pkt1] [pkt2] [pkt3] [pkt4] [pkt5]
↓ (GRO merge tại driver)
[GRO merged packet]
↓
Create 1 SKB
↓
Xử lý 1 lần thôi 🧠✨→ GRO giúp giảm số lượng SKB tạo ra → ít gọi alloc/free → tiết kiệm CPU và tăng tốc độ xử lý.
| Gói tin đến | Với GRO tắt | Với GRO bật |
|---|---|---|
| 5 gói | → 5 SKB | → 1 SKB (gộp) |
| CPU xử lý | 5 lần TCP/IP | 1 lần thôi |
| Hiệu quả | Tốn CPU hơn | Nhanh hơn, ít overhead |
2.5. Budget / Time trong SoftIRQ là gì?
Budget và time trong SoftIRQ là một trong những cơ chế kiểm soát quan trọng nhất của Linux kernel networking. Chúng đóng vai trò chống bão SoftIRQ và giữ cho CPU không bị lock quá lâu vào việc xử lý network packet.
Budget – Giới hạn số gói tin được xử lý mỗi lần
- Là số lượng tối đa các gói tin mà kernel cho phép xử lý trong mỗi vòng SoftIRQ (NET_RX).
- Mặc định
net.core.netdev_budget = 300(có thể thay đổi trong/proc/sys/net/core/) - Cứ mỗi lần SoftIRQ (hoặc
ksoftirqd) chạy → chỉ xử lý tối đabudgetgói từ NAPI poll
→ Mục đích để giới hạn công việc, tránh chiếm CPU mãi.
Time – Thời gian giới hạn xử lý SoftIRQ
- Là thời gian tối đa mà kernel cho phép xử lý SoftIRQ liên tục trong một lần kích hoạt.
- Tùy kernel, mặc định thường ~2ms (2,000,000 ns)
- Dùng trong một số logic như
__do_softirq()để dừng xử lý nếu đã mất quá nhiều thời gian, dù chưa hết budget.
→ Mục đích giữ cho latency hệ thống ổn định, không để xử lý SoftIRQ nuốt trọn CPU.
- Phải có budget/time vì nếu không giới hạn:
- Gói tin đến liên tục → SoftIRQ cứ chạy mãi không dừng
- Làm ứng dụng user-space không có cơ hội chạy
- Gây ra hiện tượng CPU lock → hệ thống lag hoặc nghẽn
Khi budget/time bị vượt kernel sẽ:
- Tạm dừng xử lý SoftIRQ
- Đánh dấu SoftIRQ là pending
- Wake up
ksoftirqd/Nđể xử lý phần còn lại
→ Tức là budget/time hết → gọi tới ksoftirqd để xử lý bù
Sơ đồ luồng đơn giản:
SoftIRQ (NET_RX) chạy
↓
Có nhiều gói trong NAPI?
↓
Đã xử lý đủ budget (300 gói)? → YES → Stop, wake ksoftirqd
Đã hết thời gian (2ms)? → YES → Stop, wake ksoftirqd
↓
Nếu còn trong hạn mức → Tiếp tục xử lýNhư vậy tổng kết lại ta có bảng so sánh như dưới.
| Thuộc tính | Vai trò | Mặc định | Có thể chỉnh |
|---|---|---|---|
budget | Số gói xử lý/lượt SoftIRQ | 300 | /proc/sys/net/core/netdev_budget |
time | Thời gian tối đa xử lý | ~2ms | Không trực tiếp chỉnh, nhưng có thể patch kernel |
Sơ đồ SoftIRQ xử lý gói tin với budget & time
(IRQ từ NIC)
↓
+-------------------+
| napi_schedule() | ← Đánh dấu NAPI cần xử lý
+-------------------+
↓
+-------------------+
| SoftIRQ (NET_RX) |
+-------------------+
↓
| Bắt đầu vòng poll() |
↓
| Bắt đầu đếm: |
| budget_used = 0 |
| time_spent = 0 |
↓
+------------------------------------+
| Trong khi: |
| - Có gói tin trong NAPI queue |
| - budget_used < netdev_budget |
| - time_spent < TIME_LIMIT |
+------------------------------------+
↓
| Gọi napi->poll() |
| ↑ xử lý 1 batch gói tin |
↓
[Tăng budget_used, đo time_spent]
↓
Nếu còn quota/time → Lặp lại vòng
↓
+-----------------------------+
| Nếu HẾT budget hoặc time: |
| - Đánh dấu còn việc |
| - Wake up ksoftirqd/N |
+-----------------------------+
↓
[Phần việc còn lại sẽ do ksoftirqd/N xử lý]2.6. Backlog – Giải pháp chống nghẽn cổ chai được lưu trên RAM (sử dụng cho các thiết bị sử dụng drive cũ).
2.6.1. Tổng quan về Backlog.
- Nếu user-space (Ceph OSD) đọc gói không kịp, mà gói mới vẫn tới:
- Kernel đưa gói vào backlog queue (dự phòng).
- Backlog là một queue nội bộ của kernel cho từng socket → tránh mất gói, nhưng nếu backlog cũng đầy thì gói bị drop.
- Có thể thấy backlog như một buffer đệm giúp tránh mất dữ liệu nếu user-space xử lý chưa kịp.
- Backlog được lưu trong RAM, cụ thể là trong các queue nội bộ của kernel, như sau:
- Backlog ở cấp độ network stack (softnet_data.backlog – lưu gói chưa xử lý khi SoftIRQ tạm thời bị bận):
- Khi SoftIRQ (NET_RX_SOFTIRQ) không kịp xử lý các gói mới, kernel sẽ xếp gói vào một queue backlog (mỗi CPU có một
softnet_datariêng). - Các gói này sẽ được xử lý sau, khi CPU rảnh hoặc khi
ksoftirqd/Nchạy. - Được lưu trong RAM, dưới dạng các cấu trúc
skb(socket buffer).
- Khi SoftIRQ (NET_RX_SOFTIRQ) không kịp xử lý các gói mới, kernel sẽ xếp gói vào một queue backlog (mỗi CPU có một
- Backlog ở cấp độ socket (sk_backlog – lưu gói đã được đưa tới đúng socket, nhưng kernel vẫn còn đang xử lý, hoặc chưa chuyển sang queue recv của user space):
- Mỗi socket (ví dụ như socket mà Ceph-osd mở để nhận request) có thể chứa gói nhận vào trong:
- Receive queue: nơi gói được đẩy sau khi hoàn tất TCP/IP stack.
- Nếu socket đang bận, kernel có thể đẩy tạm vào
sk_backlog. - Tất cả cũng là RAM, vì kernel cần tốc độ cao để không làm mất gói.
- Backlog ở cấp độ network stack (softnet_data.backlog – lưu gói chưa xử lý khi SoftIRQ tạm thời bị bận):
| Tên gọi | Vị trí | Vai trò chính |
|---|---|---|
softnet_data.backlog | Tầng network stack kernel (SoftIRQ) | Lưu gói chưa xử lý khi SoftIRQ tạm thời bị bận |
sk_backlog | Tầng socket (người dùng) | Lưu gói đã đến đúng socket, nhưng chưa xử lý kịp |
Bạn có thể thấy các gói bị backlog/drop bằng lệnh dưới đây, cột thứ 2 → gói bị drop do backlog đầy.
cat /proc/net/softnet_statHoặc kiểm tra buffer socket:
ss -m # hiển thị memory usage của socket2.6.2. Khi nào gói bị giữ lại (ở backlog hoặc NIC) sẽ được xử lý tiếp?
Dù gói nằm ở RAM hay trên NIC, nó sẽ được poll lại trong vòng xử lý kế tiếp của SoftIRQ, hoặc bởi ksoftirqd/N nếu SoftIRQ bị quá tải.
Trường hợp 1: Không dùng NAPI (xử lý qua softnet_data.backlog)
Gói tin được tạo skb ngay khi IRQ xảy ra, và đưa vào RAM backlog → softnet_data.backlog
Khi nào sẽ được xử lý lại?
- Kernel sẽ tiếp tục gọi lại
NET_RX SoftIRQvòng sau - Có thể là:
- Ngay lập tức sau khi xử lý xong một batch SoftIRQ
- Hoặc nếu SoftIRQ chuyển qua cho
ksoftirqd/N, thì thread này sẽ xử lý backlog đó
- Quá trình lặp liên tục theo scheduler hoặc timer (HZ ticks)
Trường hợp 2: Dùng NAPI (giữ gói ở NIC ring buffer)
Gói chưa tạo skb, vẫn nằm trong buffer phần cứng của NICnapi->poll() chỉ lấy ra được số lượng giới hạn (do netdev_budget)
Khi nào được gọi lại?
- Khi driver gọi
napi_schedule()→ NAPI được đánh dấu “có việc” - Kernel scheduler tiếp tục gọi lại
napi->poll()trong vòng SoftIRQ tiếp theo - Nếu SoftIRQ bận → chuyển sang thread
ksoftirqd/Nxử lý tiếp - Mỗi vòng
poll():- Lấy thêm gói từ NIC
- Xử lý tiếp cho đến khi hết gói hoặc hết
budget
Cơ chế lặp lại xử lý phụ thuộc vào.
| Yếu tố | Ảnh hưởng |
|---|---|
netdev_budget | Số lượng gói tối đa xử lý mỗi vòng poll |
| SoftIRQ latency | Nếu SoftIRQ bận thì xử lý sẽ delay |
ksoftirqd/N hoạt động | Nếu SoftIRQ bị đẩy qua đây thì xử lý gói sẽ bị trễ hơn |
| System load | Nếu CPU quá tải → thời điểm poll lại sẽ chậm |
Tóm tắt
| Gói nằm ở đâu | Khi nào được gọi xử lý lại? |
|---|---|
softnet_data.backlog (non-NAPI) | Khi NET_RX SoftIRQ tiếp tục chạy hoặc ksoftirqd/N hoạt động |
| NIC buffer (NAPI) | Khi napi->poll() được gọi lại bởi SoftIRQ hoặc ksoftirqd/N |
2.7. User Space
2.7.1. Phần CPU xử lý cho User Space – nơi Ceph OSD thực sự xử lý logic
- Ví dụ
ceph-osdlà process chạy ở user space. - Khi gói tin đã nằm ở receive queue, OSD dùng syscall như
recv()để đọc gói từ socket. - Sau khi nhận:
- Phân tích gói: loại request gì? Ghi file à?
- Chia file thành object.
- Xác định object đó nằm trên OSD nào (dựa vào CRUSH).
- Gửi tiếp hoặc ghi xuống local disk.
| Giai đoạn | Ai xử lý | Mức độ tốn CPU |
|---|---|---|
| Hard IRQ | Kernel | Rất nhẹ, rất nhanh |
| SoftIRQ + TCP Stack | Kernel | Vừa, batch gói |
| Backlog xử lý + socket buffer | Kernel | Không quá nặng |
| Ceph OSD logic (chia file, CRUSH) | User | Tốn CPU (logic nhiều) |
| Ghi đĩa (IO scheduler, block dev) | Kernel | Có thể block CPU |
Ví dụ luồng xử lý request trong Ceph OSD thể hiện mối quan hệ của chúng
+-------------------+
| NIC Buffer |
| (gói tin đến) |
+-------------------+
|
v
+-------------------------+
| Hard IRQ (IRQ handler) |
| - Điểm danh và ngắt |
| - Gọi napi_schedule() |
+-------------------------+
|
v
+-------------------------+
| SoftIRQ (NET_RX) |
| - poll() lấy gói từ NIC |
| - Đưa vào TCP/IP stack |
| - Gán vào socket OSD |
+-------------------------+
|
v
+-------------------------+
| Kernel Socket Queue |
| (sk_buff cho Ceph OSD) |
+-------------------------+
|
+-------------------+
| Backlog Queue | <-- Nếu user-space đọc chậm
+-------------------+
|
v
+-------------------------+
| User space (ceph-osd) |
| - recv() lấy gói |
| - Phân tích request |
| - CRUSH map chọn OSD |
| - Chia file thành obj |
+-------------------------+
|
v
+-------------------------+
| Kernel Block Layer |
| - IO Scheduler |
| - Device driver (disk) |
+-------------------------+
|
v
+-------------------+
| Storage Disk |
| (ghi object) |
+-------------------+Ý chính trong sơ đồ:
- Hard IRQ = người gác cổng chỉ báo có gói tin đến (giống như nhân viên lễ tân quầy cà phê).
- SoftIRQ = người sắp xếp sẽ tiếp nhận nhiều gói, đưa vào socket hàng loạt (lấy các thông tin khách như dùng cà phê gì, có dùng đá lạnh không, số lượng bao nhiêu ly).
- Backlog = phòng chờ dùng khi Ceph OSD đọc chậm (giống kiểu lượng khách mua cà phê quá đông sẽ chờ phục vụ tại đây).
- Ceph-osd (user space) = người xử lý logic chính ví dụ chia object, CRUSH, replication (giống như đây là nhân viên trực tiếp pha cà phê, nếu pha kịp cà phê cho khách thì coi như xong, nếu không kịp thì nói khách chờ ở Backlog một lát sẽ tới lượt phục phụ tiếp).
- Disk IO (kernel block layer) = tầng cuối cùng ghi dữ liệu xuống đĩa (giống kiểu cà phê đã pha xong, bàn giao cho khách hàng để kết thúc phục vụ).
2.7.2. Phân biệt CPU sử dụng cho User Space và SoftIRQ
Có một câu hỏi đặt ra User Space CPU xử lý gì, còn SoftIRQ xử lý gì? Vẫn tiếp tục lấy ví dụ phục vụ quán cà phê và sau đó mình sẽ liên hệ đến Ceph OSD để bạn dễ hình dung hơn.
| Thành phần | Ví dụ quán cà phê | Xử lý cái gì trong thực tế? |
|---|---|---|
| SoftIRQ | Nhân viên nhận order, ghi phiếu, xếp vào queue | – Nhận gói tin từ NIC – Xử lý TCP/IP stack – Đẩy gói vào socket (Ceph-osd) |
| User Space (Ceph-osd) | Barista chính sẽ pha cà phê theo order của khách | – Đọc dữ liệu từ socket – Phân tích request Ceph – CRUSH map – Ghi/replicate object – Gửi trả kết quả cho client |
Diễn giải quy trình như một dòng khách vào quán:
👨💼 Nhân viên gác cửa (Hard IRQ)
➡️ Báo có khách mới đến (gói tin tới)
➡️ Gọi SoftIRQ lo tiếp nhận
👨🔧 SoftIRQ (network stack)
➡️ Nhận khách (lấy thông tin gói tin TCP/IP)
➡️ Ghi phiếu order, xếp phiếu vào hàng chờ Ceph-osd (socket buffer)
👩🍳 User space (Ceph-osd)
➡️ Đọc từng phiếu order
➡️ Pha cà phê theo loại (write, read, snapshot, heartbeat, recovery...)
➡️ Trả cà phê, hoặc gửi sang quán khác (replicate)SoftIRQ xử lý gì?
- Là công việc tầng mạng trong kernel (nhân viên “tiếp tân kỹ thuật”):
- Nhận batch gói tin từ NIC (qua poll())
- Áp dụng TCP/IP, checksum, reassembly nếu cần
- Tìm đúng socket
- Đẩy
sk_buffvào hàng chờ của socket màceph-osdđang mở
SoftIRQ không biết nội dung request là gì, chỉ là “Có khách, gửi cho người pha chế”
User space (Ceph-osd) xử lý gì?
- Đây là tầng logic của Ceph (Barista chính!):
- Đọc dữ liệu từ socket (
recv()) - Giải mã message Ceph
- Phân tích: ghi object? replicate? xóa file?
- Chọn OSD (CRUSH map), chia nhỏ object nếu cần
- Ghi xuống đĩa hoặc gửi cho OSD khác
- Trả về kết quả cho client
- Đọc dữ liệu từ socket (
Ceph-osd mới là nơi “biết ý định của khách” (muốn uống gì? replicate đi đâu? xóa file nào?…)
Liên hệ đến CPU
| Loại CPU dùng | Công việc điển hình |
|---|---|
| CPU xử lý SoftIRQ | – Nhận, decode TCP/IP – Ghi dữ liệu vào socket buffer → Xử lý nhanh, ưu tiên batch |
| CPU xử lý User-space (ceph-osd) | – Gọi recv() đọc gói– Phân tích logic Ceph – Ghi đĩa / gửi sang OSD khác → Thường là CPU bận nhất |
- Ceph cần nhiều core cho user space, còn SoftIRQ nên được pin và tối ưu (rps, irq affinity) để không bottleneck. Nếu Ceph-osd bận (pha không kịp)?
- SoftIRQ đẩy gói vào socket → nhưng buffer đầy → đẩy sang backlog → nếu vẫn chậm → drop
- Giống như: khách đến, tiếp tân ghi phiếu xếp hàng, nhưng barista pha chậm → backlog full → khách bực bỏ về!
| So sánh | SoftIRQ (Kernel) | User Space (Ceph-osd) |
|---|---|---|
| Giao tiếp gì | Nhận packet từ NIC | Nhận từ socket (đã decode TCP) |
| Biết request không? | ❌ Không (chỉ network packet TCP) | ✅ Có (decode request Ceph) |
| Tốn CPU? | Trung bình, batch nhanh | Cao (phân tích, tính toán, IO) |
| Vai trò | Trung gian vận chuyển | Xử lý logic, lưu trữ, phản hồi |
3. Hiểu về Ksoftirqd/N
3.1. Ksoftirqd/N là gì?
Khi CPU đang bận (đang trong user space, hoặc đã xử lý SoftIRQ quá quota), kernel không thể bỏ dở công việc đang làm để xử lý SoftIRQ ngay, mà sẽ đánh thức thread ksoftirqd/N, vốn là thread có ưu tiên thấp hơn, để hỗ trợ xử lý một số công việc của SoftIRQ — khi CPU rảnh nó sẽ quay lại xứ lý các tác vụ của SoftIRQ theo lịch trình bình thường.
Nó là thread thay mặt cho SoftIRQ để chạy hàm napi->poll(), thực hiện việc lấy gói tin từ NIC và xử lý vào TCP/IP stack — y hệt như SoftIRQ làm, chỉ khác về ngữ cảnh và thời điểm chạy.
Hiểu đơn giản nhé, ví dụ bạn là CPU đang làm quá nhiều việc, có một người khác ví dụ SoftIRQ tới nhờ bạn xử lý hàng đống gói tin.
- Nếu bạn làm luôn → bạn bỏ dở mọi thứ khác → quá tải.
- Thay vì vậy, bạn nhờ người phụ tá ưu tiên thấp đó chính là ksoftirqd/N xử lý giúp bạn khi bạn quá bận.
Thực tế ví dụ khi bạn thấy hệ thống bị DDoS, hoặc lưu lượng mạng rất cao. Bạn sẽ thấy ksoftirqd/0, ksoftirqd/1 bắt đầu tăng %CPU usage rất cao
→ Chính là vì chúng đang xử lý phần việc còn lại của SoftIRQ NET_RX — lấy gói tin từ card mạng, đẩy vào TCP/IP stack, phân phối tới socket để phụ cho SoftIRQ
Sơ đồ xử lý SoftIRQ và vai trò của ksoftirqd/N
(Gói tin đến)
↓
+-----------------+
| NIC (Card mạng)|
+-----------------+
↓
[HardIRQ]
↓
+------------------+
| IRQ Handler | <----------------+
+------------------+ |
↓ |
+------------------+ [Nếu CPU bận]
| Raise SoftIRQ | |
+------------------+ |
↓ |
+----------------------------------------+ |
| CPU xử lý ngay bằng: do_softirq() | |
| (nếu CPU đang ở kernel-space, rảnh) | |
+----------------------------------------+ |
↓ |
[Xử lý SoftIRQ ngay lập tức] |
|
|
┌─────────────────────────────┘
↓
[Không xử lý SoftIRQ ngay được]
↓
+-----------------------------+
| Wake up ksoftirqd/N (per CPU)|
+-----------------------------+
↓
+------------------+
| ksoftirqd/N |
| (kernel thread) |
+------------------+
↓
[Xử lý SoftIRQ như 1 tiến trình]Các loại SoftIRQ phổ biến:
NET_RX → Nhận network packet (gói tin vào)
NET_TX → Gửi network packet (gói tin ra)
BLOCK → Xử lý I/O khối (ổ cứng, SSD)
TIMER → Xử lý timer (clock events)
TASKLET → Cơ chế trì hoãn nhẹ khácLuồng xử lý network packet từ NIC đến App
Gói tin đến (Ethernet frame)
↓
+----------------+
| NIC |
| (card mạng) |
+----------------+
↓
Gửi IRQ (HardIRQ)
↓
+----------------------+
| IRQ Handler |
| (gọi napi_schedule())|
+----------------------+
↓
+------------------------------+
| SoftIRQ (NET_RX) |
| Xử lý gói nếu CPU rảnh |
+------------------------------+
↓
+---------------------+ ↓ +-------------------------+
| do_softirq() | <-----+-----> | ksoftirqd/N (nếu CPU bận)|
+---------------------+ +-------------------------+
↓
Gói được chuyển vào TCP/IP stack
↓
+-----------------------------+
| IP layer → TCP/UDP layer |
+-----------------------------+
↓
Tìm socket phù hợp (port match)
↓
+---------------------------------------+
| Socket trong kernel (`struct sock`) |
| → Nếu app chưa recv, đẩy vào |
| `sk_backlog` hoặc `sk_receive_queue`|
+---------------------------------------+
↓
App gọi `recv()` nhận dữ liệu
↓
+-------------------+
| User-space App |
+-------------------+Trình tự xử lý các bước:
- NIC nhận packet từ mạng → gửi IRQ.
- IRQ handler gọi NAPI để xử lý.
- Nếu CPU rảnh → xử lý ngay qua SoftIRQ (NET_RX).
- Nếu bận → đẩy qua
ksoftirqd/Nđể nhờ xử lý. - Gói được đẩy lên TCP/IP stack.
- Xác định socket → đưa gói vào backlog hoặc recv queue.
- App gọi
recv()→ gói vào user-space.
Tưởng tượng đơn giản
NIC gói mới →
IRQ →
SoftIRQ: "Tôi sẽ gọi napi->poll() để xử lý"
Nếu bận:
SoftIRQ: "Gọi anh ksoftirqd/N xử lý giúp"
ksoftirqd/N:
→ "OK, tôi gọi napi->poll() cho ông đây"3.2. Tình huống chính khiến SoftIRQ không xử lý ngay và kernel phải nhờ ksoftirqd/N xử lý thay.
Có 2 tình huống chính khiến SoftIRQ không xử lý ngay và kernel phải nhờ ksoftirqd/N xử lý thay đó là:
CPU đang xử lý user-space (user context)
- Khi SoftIRQ được kích hoạt (via
raise_softirq()), nhưng lúc đó:- CPU đang chạy code user (VD: một ứng dụng đang chạy),
- Không thể nhảy vào xử lý SoftIRQ ngay lập tức → vì không an toàn (SoftIRQ xử lý trong kernel context)
→ Kernel sẽ đặt cờ pending, sau đó wake up ksoftirqd/N để thread này xử lý SoftIRQ khi có CPU rảnh hơn.
CPU đã chạy SoftIRQ quá quota giới hạn
- Linux đặt quota cho xử lý SoftIRQ (mặc định là 2ms hoặc 10 gói/lượt)
- Biến
netdev_budgettrong/proc/sys/net/core/
- Biến
- Nếu vượt quá quota đó (tức là xử lý lâu quá trong ngữ cảnh ngắt):
- Kernel ngưng xử lý ngay (để tránh CPU bị “lock”)
- Ghi nhớ lại phần SoftIRQ chưa xử lý xong
- Sau đó wake up
ksoftirqd/Nđể tiếp tục làm nốt phần việc còn lại
Ngoài ra, kernel còn có thể chuyển sang ksoftirqd/N trong các tình huống:
- Đang ở trong một đoạn code không cho phép xử lý ngắt mềm (SoftIRQ-off region)
- Gặp lock contention hoặc preemption bị disable tạm thời
- Khi ưu tiên xử lý ứng dụng người dùng hơn là bottom-half
4. Turning
Phân chia riêng core xử lý SoftIRQ và core xử lý user-space
Việc phân chia riêng core xử lý SoftIRQ và core xử lý user-space là một chiến lược cực kỳ phổ biến trong hệ thống hiệu năng cao (high-performance networking).
Mục tiêu là giảm tranh chấp CPU, từ đó giảm khả năng phải dùng ksoftirqd/N và tối ưu latency.
Vì sao lại giảm được việc phải dùng ksoftirqd/N? Hãy nhớ lại: ksoftirqd/N chỉ được gọi khi:
- CPU đang ở user-space → không thể xử lý SoftIRQ ngay
- Hoặc SoftIRQ đã xử lý quá quota → phải hoãn lại
→ Nếu bạn tách riêng hẳn 1 hoặc vài core chỉ chuyên xử lý ngắt và SoftIRQ, thì:
- CPU đó luôn ở kernel-space, rảnh để xử lý SoftIRQ ngay lập tức
- Không bị ứng dụng chiếm mất thời gian
- Không vượt quota vì không bị gián đoạn
→ Không cần nhờ đến ksoftirqd/N nhiều nữa!
Hình dung đơn giản:
Trước:
[CPU 0]: App + IRQ + SoftIRQ → dễ tranh chấp → phải dùng ksoftirqd/0
Sau khi pin:
[CPU 0]: Chỉ xử lý IRQ + SoftIRQ
[CPU 1]: Chạy ứng dụng user-space
→ Không tranh giành → không phải hoãn SoftIRQ → không cần wake ksoftirqd/NNhư vậy nếu bạn phân chia rõ CPU xử lý user vs SoftIRQ, bạn sẽ giảm được tình trạng phải nhờ đến ksoftirqd/N, từ đó tăng hiệu năng cho network, giảm latency và ổn định hệ thống.
IRQ Affinity/smp_affinity
Gán IRQ của NIC vào một hoặc vài CPU cố định → Chỉ core 1 xử lý IRQ từ card mạng đó
# Gán IRQ 100 vào CPU core 1
echo 2 > /proc/irq/100/smp_affinity- Bật RSS & đủ queues:
ethtool -l ethX(channels) → số RX/TX queue ~ số core hiệu dụng cho NIC. - Pin IRQ hợp lý: tắt/bật
irqbalancehoặc tinh chỉnhsmp_affinitycho từng IRQ trong/proc/irq/*/smp_affinityđể dàn đều core. - RPS/RFS:
rps_cpuscho từng RXQ (sysfs:/sys/class/net/ethX/queues/rx-*/rps_cpus)rps_flow_cnt+net.core.rps_sock_flow_entriesđể bật RFS (steer về CPU có app).
- XPS: cấu hình
/sys/class/net/ethX/queues/tx-*/xps_cpusđể mapping TX theo CPU. - GRO: giữ GRO bật (mặc định) để giảm PPS; (LRO tránh khi cần routing).
- Vòng RX/TX ring:
ethtool -G ethX rx <N> tx <N>tăng ring nếu thấy drop ở NIC. - Backlog: nâng
net.core.netdev_max_backlognếu thấy softnet_stat báo drop (cột 2) khi tải cao. - Buffer socket: điều chỉnh kích thước vùng nhớ cho socket TCP, để có thể gánh được throughput cao hơn (
net.core.rmem_max,net.core.wmem_max,net.ipv4.tcp_rmem/wmem) vì:- Nếu buffer quá nhỏ → nhận/gửi không kịp → TCP phải chờ → giảm throughput.
- Nếu buffer quá lớn mà không cần thiết → lãng phí RAM, thậm chí gây latency tăng do full queue.
- Latency-sensitive: cân nhắc
net.core.busy_read/busy_poll(đổi CPU lấy latency thấp hơn) nếu phù hợp.
5. Phân tích một lỗi dạng CPU pressure feedback loop, là một dạng logic mà ít khi được thể hiện rõ trên dashboard monitoring.
5.1. Mình sẽ phân tích logic từng bước để các bạn dễ hình dung. Kịch bản này sẽ là một vòng luẩn quẩn (feedback loop)
Giai đoạn khởi phát:
- Đột nhiên User Space CPU tăng cao vì một lý do gì đó → ví dụ:
- Ceph OSD xử lý một batch object quá lớn
- Thread lock hoặc GC nội bộ (nếu dùng Java/Python cho service khác)
- Memory pressure khiến Ceph bị delay malloc / IO submit
→ Lúc này Ceph chưa xử lý xong packet này để tiếp tục đọc packet khác đang chờ ở socket buffer.
Giai đoạn kế tiếp:
- Trong khi đó client cũng đang tăng request nhẹ → không bất thường nhưng trùng thời điểm.
- Các gói tin tiếp tục đổ về.
- SoftIRQ (NET_RX) tiếp tục bị đánh thức để xử lý network stack, nhưng:
- Socket buffer bị đầy
- Đẩy vào backlog queue, nhưng các packet đang ở đây Ceph cũng chưa kịp đọc tới → backlog không giải phóng kịp.
→ SoftIRQ thì vẫn bị gọi lại liên tục để xử lý → CPU SoftIRQ bắt đầu chiếm nhiều.
Giai đoạn mất kiểm soát:
- SoftIRQ giờ chiếm quá nhiều core CPU → Ceph OSD không còn core CPU để để xử lý phần việc của nó.
- Trong khi đó backlog chưa được giải phóng → càng làm SoftIRQ bị gọi lại nhiều hơn.
- Các process Ceph bị chuyển sang Runnable nhưng không được chạy (Waiting cao). Nghĩa là Ceph OSD (hoặc MON/MGR) muốn được CPU xử lý, nhưng không được cấp CPU ngay dẫn đến “Waiting high” (trạng thái chờ CPU).
→ Vòng lặp này càng lúc càng dồn tài nguyên về phía SoftIRQ và User Space không có cơ hội hồi phục.
5.2. Kiểm tra trạng thái của process
Trong lệnh top hoặc htop, cột S thể hiện trạng thái hiện tại của mỗi tiến trình (process/thread). Cụ thể:
| Ký tự | Trạng thái | Ý nghĩa |
|---|---|---|
| R | Running | Process đang chạy hoặc sẵn sàng chạy trên CPU |
| S | Sleeping | Process đang ngủ ngắn hạn, chờ một sự kiện như I/O, socket, v.v. |
| D | Uninterruptible Sleep | Chờ I/O và không thể bị đánh thức tạm thời, thường là disk I/O |
| Z | Zombie | Đã kết thúc nhưng chưa được parent process thu gom |
| T | Traced/Stopped | Bị dừng (stop) hoặc đang bị debug |
I | Idle | Thread hoàn toàn nhàn rỗi, không làm gì cả, đang “ngồi chơi xơi nước” |
Dùng top hoặc htop:
- Kiểm tra phần
R(Running/Runnable) - Nếu số process Ceph ở trạng thái
Rcao, nhưng CPU idle gần 0% → nghẽn CPU
Dùng ps nếu nhiều Ceph process có trạng thái R → đang chờ CPU
ps -e -o pid,stat,comm | grep cephÝ nghĩa cụ thể trong bối cảnh này của Ceph:
- Nếu bạn thấy nhiều process
ceph-osdở trạng thái:**D**→ Đang bị kẹt I/O, có thể chờ disk, fsync, hay bị lock trên journal**R**→ Đang chạy thật sự hoặc đang tranh CPU**S**→ Bình thường, đang idle hoặc chờ socket, mạng, v.v.
Hệ quả là tắc nghẽn toàn diện
- Client IOPS giảm, dù vẫn gửi đều.
- Ceph Apply latency tăng, nhưng không phải do disk.
- SoftIRQ lên rất cao (80–90%)
- User Space lại tụt do bị SoftIRQ “cướp CPU”
- Chỉ còn cách reboot node để:
- Reset lại backlog / driver queue
- Clean up TCP stack và SoftIRQ queue
- Giải phóng toàn bộ logic kernel đang bị “kẹt vòng lặp”
5.2. Nhận định nguyên nhân
Tổng hợp hiện tượng đã mô tả
- Client Request ổn định – request đến đều, không tăng đột biến.
- IOPS & Throughput giảm đột ngột, dù workload không thay đổi.
- Latency tăng cao (apply, commit latency tăng ở OSD).
- SoftIRQ tăng cao, trong khi User Space CPU lại thấp.
- Disk là NVMe tốc độ cao, network 100G → không phải bottleneck về phần cứng.
- Reboot node OSD xong thì hoạt động trở lại bình thường.
- Các OSD process tiêu tốn CPU rất cao, tuy nhiên nhiều process lại ở trạng thái
S(sleeping).
Nghẽn ở tầng kernel networking hoặc backlog
- SoftIRQ tăng cao trong khi User Space không tương xứng cho thấy:
- Gói tin vẫn được nhận và xử lý bởi network stack (SoftIRQ).
- Nhưng socket buffer hoặc backlog bị đầy, Ceph OSD không kịp xử lý.
- Ceph OSD bị “kẹt” có thể vì chờ disk I/O, memory pressure, hoặc tranh chấp lock nội bộ.
- → Điều này khiến SoftIRQ tiếp tục bận bịu retry mà không thể đẩy sang user-space → CPU SoftIRQ cao.
Khả năng Ceph OSD bị “kẹt logic” / deadlock tạm thời
- Mỗi OSD Node sẽ có nhiều OSDs + OSD process, mỗi cái nếu tiêu tốn 100-260% CPU, nhưng CPU ở trạng thái
S. - Có thể là Ceph bị kẹt ở một mutex nào đó (locking internal data), ví dụ khi:
- MMap page cache bị đầy, tranh chấp memory trong BlueStore.
- Memory fragmentation cao, hoặc cgroup memory bị giới hạn.
- Một thread ceph bị stuck nhưng không hoàn toàn block, gây snowball effect.
Disk vẫn hoạt động tốt nhưng bị “đơ tạm”
- Sau khi reboot, disk hoạt động lại bình thường.
- Điều này có thể xảy ra nếu:
- Driver bị lỗi tạm thời, queue bị kẹt.
- NVMe controller có timeout internal, mà kernel không tự reset.
- Ceph không phát hiện lỗi để mark out OSD → dẫn đến toàn bộ node nghẽn.
5.3. Kết luận sơ bộ
Thường thì SoftIRQ tăng cao là hệ quả chứ không phải nguyên nhân gốc. SoftIRQ không bị “kẹt”, nó tăng CPU vì phải lặp lại xử lý, do các tầng sau chậm phản hồi hoặc nghẽn.
Giống kiểu SoftIRQ vẫn làm việc cực lực “xếp hàng nhận đơn”, còn User Space (ceph-osd) đang “pha cà phê quá chậm” — nên hàng dài backlog bị nghẽn.
Gốc rễ thực sự thường nằm ở:
- Ceph OSD xử lý chậm:
- Gặp tranh chấp lock
- Bị memory pressure
- Disk delay nhẹ khiến apply bị chậm
- Backlog queue bị đầy
- TCP socket bị nghẽn, không drain kịp
Khả năng cao OSD Node bị kẹt ở tầng kernel hoặc logic OSD (backlog/socket/memory lock), khiến cho SoftIRQ tăng cao còn OSD không xử lý kịp.
- Không phải lỗi disk vật lý (vì reboot xong lại chạy).
- Không do network (các node khác vẫn hoạt động).
- Có thể do Ceph OSD bị rò rỉ memory / deadlock ngắn hoặc driver NVMe lỗi ngắt tạm.
5.4. Hướng xử lý đề xuất
- Trước khi reboot node lần sau, hãy:
- Chạy
echo t > /proc/sysrq-triggerđể dump stack toàn bộ thread (xem thread nào đang block). - Kiểm tra
/proc/net/softnet_stat,netstat -s,ss -nptđể đo backlog.
- Chạy
- Giám sát socket queue backlog của Ceph:
netstat -nputw | grep ceph - Theo dõi memory fragmentation:
cat /proc/buddyinfo cat /proc/meminfo - Upgrade Ceph / kernel nếu đang dùng bản cũ – rất nhiều bản vá liên quan tới NVMe, BlueStore và backlog đã được fix trong các bản gần đây.
Kiểm tra thêm thì có thể xác định kỹ hơn là Ceph bị kẹt ở đâu cụ thể (logic, lock, hay socket).
dmesg,ceph tell osd.X dump_historic_ops, hoặc- dump stack từ
sysrq-trigger
5.5. Giải pháp về lâu dài
- Cấu hình CPU pinning: gán riêng core cho SoftIRQ và Ceph OSD để tránh tranh CPU.
- Enable RPS/XPS cho NIC: phân tán SoftIRQ trên nhiều core → giảm nguy cơ overload.
- Tăng backlog / socket buffer (
net.core.rmem_max,tcp_rmem) nếu chưa tối ưu. - Giám sát softnet_stat & /proc/interrupts → phát hiện sớm SoftIRQ overload.
- Upgrade Ceph / kernel nếu đang ở bản cũ → nhiều cải tiến về IO + SoftIRQ
6. Kết luận
Khi hệ thống Ceph OSD gặp tình trạng CPU SoftIRQ tăng đột biến, không nên vội đánh giá đây là nguyên nhân gốc. SoftIRQ thường chỉ là hệ quả của việc tầng User Space xử lý chậm (Ceph OSD bị nghẽn), dẫn đến backlog TCP bị đầy, từ đó kích hoạt SoftIRQ lặp lại liên tục — tạo nên vòng lặp tiêu tốn tài nguyên.
Việc hiểu đúng pipeline xử lý dữ liệu (từ NIC đến disk) là chìa khóa để chẩn đoán đúng bệnh. Bài viết chỉ ra rằng trong nhiều trường hợp, reboot chỉ là cách phá vòng lặp, còn giải pháp bền vững cần đến việc:
- Tách core cho SoftIRQ và Ceph OSD
- Tuning socket buffer & backlog
- Giám sát
softnet_stat,process waitingvàinterrupts
Đây là một bài học điển hình về sự tương tác giữa kernel và user space, và là cơ sở quan trọng để tối ưu hệ thống Ceph trong môi trường production quy mô lớn.
