1. Tổng quan
Trong bài viết này, mình muốn chia sẻ lại kinh nghiệm triển khai một cluster Ceph có dung lượng 20PiB và tốc độ truyền tải đạt gần 100GB/s – một trong những cluster lưu trữ mạnh mẽ nhất mà mình từng xây dựng.

Hệ thống này được thiết kế để phục vụ hàng trăm compute node với yêu cầu cao về throughput, dung lượng lưu trữ lớn, tích hợp tốt với Kubernetes và OpenStack.
2. Ceph là gì?
Ceph là hệ thống lưu trữ phân tán mã nguồn mở, phổ biến trong các private cloud, hỗ trợ ba loại lưu trữ:
- CephFS (filesystem): cho phép mount trực tiếp trên các server.
- RBD (RADOS Block Device): thay thế cho các giải pháp SAN.
- RGW (RADOS Gateway): hỗ trợ S3 và Swift API.
Ceph hỗ trợ hai loại chính để đảm bảo tính sẵn sàng:
- Replication: Dữ liệu được lưu trữ theo dạng replication, tiếng việt mình gọi là sao chép data ra thành nhiều bản (mặc định là 3 bản).
- Erasure Coding: Mã hóa dữ liệu thành các phần nhỏ (chunk) + phần dự phòng (parity) giúp tiết kiệm dung lượng.
3. Yêu cầu hệ thống
- Tốc độ xử lý dữ liệu tổng thể (throughput): ~100GB/s (tương đương 5PB/ngày).
- Dung lượng lưu trữ thực: 20PiB.
- Có thể mount như một file system.
- Tích hợp với Kubernetes (dùng volume).
- Khả năng chịu lỗi cao (nhiều ổ cứng/host bị lỗi cùng lúc).
- Chi phí tối ưu.
4. Kiến trúc tổng quan của cluster Ceph
+----------------------------------------------------------+
| Spine Switches (2) |
+---------------------+--------------------+---------------+
| |
+--------+--------+ +--------+--------+
| Leaf Switch 1 | | Leaf Switch 2 |
+--------+--------+ +--------+--------+
| |
+-----------+----------+ +-------+--------+
| OSD Servers (40 nodes) |
+-----------+----------+ +-------+--------+
| |
+-------+--------+ +--------+--------+
| Disk Enclosures (40 enclosures) |
+-----------------+-------------------+- Racks: 10
- OSD Servers: 40 nodes
- Disk Enclosures: 40 enclosures
- MON Servers: 5 nodes
- Switch: 4 Leaf + 2 Spine (Mellanox SN4600C)
5. Chi tiết phần cứng
- Server: Dell R740xd
- Ổ cứng lưu trữ: 14TB Ultrastar DC HC530 (WD), tốc độ ~250MB/s
- Ổ cứng metadata: Dell 1.6TB NVMe
- Network:
- Card mạng Mellanox ConnectX-6 2x100GbE/IB
- Switch SN4600C (64-port, Spectrum-3)
- Cáp mini-SAS x2/enclosure
- PCIe 3.0 x8 cho HBA → băng thông ~15GB/s/server
- Disk.
- Không cắm HDD trực tiếp trên node.
- Tất cả 120 HDD đều nằm trong 2 thiết bị DAS (Disk Enclosures).
- Chỉ có 4 ổ NVMe SSD là gắn trong node dùng cho:
- Metadata pool.
- DB/WAL device trong BlueStore (giúp tăng tốc truy cập).
| Loại ổ | Số lượng | Vị trí vật lý | Vai trò trong Ceph |
|---|---|---|---|
| HDD | 120 | – 60 HDD trong Disk Enclosure #1 (DAS) – 60 HDD trong Disk Enclosure #2 (DAS) | Dữ liệu chính (OSD daemon) |
| NVMe | 4 | Gắn trực tiếp trong server node | Metadata hoặc WAL, DB (BlueStore) |
- RAM
- Mỗi node có 124 OSD:
- 120 OSDs từ HDD (qua 2 enclosures DAS),
- 4 OSDs từ NVMe SSD (metadata or DB/WAL).
- Mỗi node có 124 OSD:
| Thành phần | Số lượng | RAM/OSD (ước lượng) | Tổng RAM |
|---|---|---|---|
| OSD từ HDD | 120 | 2–3 GB | 240–360 GB |
| OSD từ NVMe | 4 | 3–6 GB | 12–24 GB |
| Tổng cộng | ~256–384 GB |
Như vậy 124 OSDs/node, nên trang bị ít nhất 256GB RAM cho node đó và lý tưởng là 384–512GB để có hiệu suất ổn định.
Sau này khi lên cụm, bạn hãy benchmark hoặc khi chạy thực tế bạn có thể xem sử dụng RAM thực tế per OSD bằng lệnh dưới.
ceph daemon osd.X perf dump | jq '.bluestore.cache' # hoặc dùng `dump_mempools`Bạn cũng có thể kiểm tra memory limit hiện tại:
ceph config get osd.X osd_memory_target6. Tối ưu hiệu suất
6.1. CPU.
- Ban đầu mỗi node được kết nối trực tiếp với 2 thiết bị lưu trữ DAS (Disk Enclosures), mỗi enclosure chứa 60 ổ cứng HDD enterprise.
- Server sử dụng CPU Intel Xeon Gold 6244 có:
- 8 cores, 16 threads,
- Tổng cộng 16 vCPU.
- Tổng cộng mỗi node phải chạy 124 OSD daemon:
- 120 OSD cho HDD (2 enclosures × 60 ổ đĩa),
- 4 OSD cho SSD NVMe (metadata).
- Vấn đề phát sinh:
- Ngay cả khi chưa có truy cập từ phía client, CPU đã sử dụng >60% — nghĩa là không còn nhiều tài nguyên để xử lý thêm.
- Giải pháp:
- Chuyển sang dùng Intel Xeon Gold 6258R mỗi con có:
- 28 cores, 56 threads.
- Là bản
rebrandgiá rẻ của dòng cao cấp Xeon Platinum 8280 (giá cũ $10.000, giờ chỉ ~$3.950).
- CPU này có PassMark ~63.059 điểm → đủ sức xử lý hơn 60 OSD daemon/node.
6.2. Tối ưu IO disk
- Các ổ cứng WD Ultrastar 14TB 7200rpm:
- Hỗ trợ đọc/ghi tuần tự (sequential) lên tới 250MB/s mỗi ổ.
- Mỗi disk enclosure có 60 ổ → tốc độ tổng:
250MB/s × 60 = 15.000MB/s = 15GB/s
=> Đây là giới hạn lý thuyết về throughput của cả enclosure.
6.3. PCIe 3.0 x8 (Kết nối từ HBA vào CPU)
- Các HBA (Host Bus Adapter) gắn vào khe PCIe 3.0 x8, mỗi khe có:
- Băng thông tối đa 7.880MB/s (gần 8GB/s).
- Mỗi server có 2 card HBA → tổng throughput:
7.880MB/s × 2 = ~15.760MB/s = ~15GB/s
=> Phù hợp với throughput của ổ cứng như tính ở trên → không bị nghẽn ở mức PCIe.
6.4. mini-SAS & Multipath (Kết nối tới enclosure)
- Mỗi mini-SAS cable có:
- 4 kênh truyền (lanes),
- Mỗi kênh: 12 Gbps → tổng: 48Gbps = 6GB/s/cáp.
- Mỗi enclosure được kết nối:
- 2 cáp mini-SAS từ 2 HBA card trên mỗi server.
=> Tổng throughput qua 2 cáp mini-SAS:
6GB/s × 2 = 12GB/sVới multipath, mỗi ổ đĩa đi qua 2 đường khác nhau → tăng độ sẵn sàng và đảm bảo redundancy.
| Thành phần | Throughput tối đa ước tính |
|---|---|
| Ổ HDD (60 × 250MB/s) | 15 GB/s |
| PCIe 3.0 x8 ×2 | ~15 GB/s |
| mini-SAS (2 cáp) | 12 GB/s |
| Ethernet 2x100G | ~25 GB/s tổng, chia đôi |
- Như vậy
- mini-SAS sẽ có nghẽn cổ chai nhẹ (12GB/s).
- Tuy nhiên, tổng thể vẫn tương thích tốt với throughput từ ổ cứng và network (100GbE).
Đây là luồng dữ liệu từ ổ đĩa → HBA → PCIe → CPU → card mạng → mạng trong một server Ceph OSD:
[Ổ đĩa HDD (x60/enclosure)]
│
╭──────────┴──────────╮
│ mini-SAS Cable │ (2 sợi cáp/Enclosure)
╰──────────┬──────────╯
│
[HBA Adapter x2]
│
╭────────────┴────────────╮
│ PCIe 3.0 x8 Slots │ (~7.88 GB/s mỗi khe)
╰────────────┬────────────╯
│
[CPU Intel Xeon 6258R]
│
╭─────────────┴─────────────╮
│ RAM/Cache │
╰─────────────┬─────────────╯
│
╭─────────────┴─────────────╮
│ Mellanox NIC (2x100GbE) │
╰─────────────┬─────────────╯
│
[Switch Leaf → Spine]
│
[Network cluster Ceph toàn hệ thống]Luồng hoạt động như sau:
- Dữ liệu được ghi hoặc đọc từ 60 ổ đĩa trong enclosure.
- Dữ liệu truyền qua 2 cáp mini-SAS, mỗi cáp cung cấp ~6GB/s → tổng ~12GB/s.
- Cáp kết nối đến 2 HBA adapter, gắn vào 2 khe PCIe 3.0 x8, cung cấp băng thông tổng ~15GB/s.
- CPU xử lý yêu cầu của OSD daemon, quản lý IO, erasure coding và trao đổi metadata.
- Card mạng Mellanox ConnectX-6 2x100GbE truyền dữ liệu ra ngoài qua bonding (active-active).
- Dữ liệu đi qua switch leaf → spine, rồi tới các node khác (client, MON, MDS, v.v.).
6.5. Network
Trong một cluster Ceph lớn, nơi mà băng thông network lên tới hàng trăm gigabit mỗi giây, việc cấu hình network đúng cách là yếu tố then chốt để đạt hiệu suất cao và ổn định. Phần này sẽ giải thích các tinh chỉnh như MTU (Jumbo Frames), bonding, VLAN và tối ưu về IRQ/NUMA.
6.5.1 Jumbo Frames
Mặc định:
- MTU (Maximum Transmission Unit) mặc định của Ethernet là 1500 bytes.
- Nếu phải truyền lượng dữ liệu lớn, gói nhỏ khiến CPU load tăng do cần xử lý nhiều gói hơn → giảm hiệu suất.
Tinh chỉnh:
- Đặt MTU = 9000 trên các server (giá trị jumbo frame) → tăng lượng dữ liệu truyền trong mỗi gói.
- Trên các thiết bị Mellanox, MTU có thể lên tới 9144 → tối đa hóa hiệu suất phần cứng.
6.5.2. Cấu hình Network cho MON node và OSD node
MON Node (Monitor Server):
- Chỉ sử dụng network public (quản lý + giao tiếp client).
- Sử dụng bonding 2 card mạng vật lý theo chuẩn 802.3ad (LACP – Link Aggregation Control Protocol).
transmit-hash-policy: layer3+4→ cân bằng tải dựa trên IP + Port.
Ví dụ YAML cấu hình:
# /etc/netplan/01-netcfg.yaml on MON nodes:
# This file describes the network interfaces available on your system
# For more information, see netplan(5).
network:
version: 2
renderer: networkd
ethernets:
eno1:
dhcp4: false
dhcp6: false
addresses: [ 10.101.77.41/22 ]
routes:
- to: 10.100.148.0/22
via: 10.101.79.254
ens1:
match:
macaddress: b8:59:9f:d9:c4:e4
set-name: ens1
ens8:
match:
macaddress: b8:59:9f:d9:c6:30
set-name: ens8
bonds:
bond1:
mtu: 9000
dhcp4: false
dhcp6: false
interfaces: [ ens1, ens8 ]
addresses: [ 10.101.69.41/22]
nameservers:
addresses: [10.100.143.21, 10.100.143.22]
gateway4: 10.101.71.254
parameters:
mode: 802.3ad
lacp-rate: fast
mii-monitor-interval: 100
transmit-hash-policy: layer3+4OSD Node (Data Node):
- Dùng 2 subnet song song:
- Public: cho MON/client.
- Cluster backend: giữa các OSD với nhau → cực kỳ quan trọng với Ceph.
- Do đó, ngoài cấu hình bond như trên, OSD còn có VLAN riêng biệt cho backend:
# /etc/netplan/01-netcfg.yaml on OSD nodes:
# This file describes the network interfaces available on your system
# For more information, see netplan(5).
network:
version: 2
renderer: networkd
ethernets:
eno1:
dhcp4: false
dhcp6: false
addresses: [ 10.101.77.1/22 ]
routes:
- to: 10.100.148.0/22
via: 10.101.79.254
ens1:
match:
macaddress: b8:59:9f:d9:c6:18
set-name: ens1
ens8:
match:
macaddress: b8:59:9f:d9:c6:1c
set-name: ens8
bonds:
bond1:
mtu: 9000
dhcp4: false
dhcp6: false
interfaces: [ ens1, ens8 ]
addresses: [ 10.101.69.1/22]
nameservers:
addresses: [10.100.143.21, 10.100.143.22]
gateway4: 10.101.71.254
parameters:
mode: 802.3ad
lacp-rate: fast
mii-monitor-interval: 100
transmit-hash-policy: layer3+4
vlans:
bond1.2072:
mtu: 9000
id: 2072
link: bond1
addresses: [ 10.101.73.1/22 ]→ Tách VLAN giúp phân luồng traffic giữa nội bộ Ceph và public network.
6.5.3. Tối ưu NUMA và IRQ affinity cho Mellanox NIC
NUMA và IRQ affinity – đây là phần kỹ thuật khá hardcore nếu bạn chưa từng làm việc sâu với hệ thống network băng thông cao.
Vấn đề CPU socket, RAM và PCIe không chia sẻ tài nguyên.
- Trong một máy chủ đời mới hiện nay thường có 2 CPU (dual-socket), thì mỗi CPU (gọi là socket A và socket B):
- Có RAM riêng (gọi là RAM A và RAM B).
- Có các khe PCIe riêng — nơi bạn cắm card mạng, card HBA v.v…
Ví dụ:
Card mạng Mellanox được gắn vào khe PCIe nằm trên socket A.
Khi dữ liệu từ card mạng đi vào CPU nhưng lại bị xử lý trên socket B, nó sẽ phải đi qua đường QPI bus (QuickPath Interconnect) giữa 2 socket.
- Điều này dẫn đến:
- Tăng độ trễ (vì phải đi xa hơn trong hệ thống).
- Giảm băng thông (vì QPI dù nhanh cũng không bằng xử lý nội bộ).
- Làm giảm hiệu suất tổng thể của hệ thống mạng.
Giải pháp tối ưu hóa là xử lý ngắt (IRQ) theo NUMA.
Mỗi khi một sự kiện xảy ra (ví dụ: dữ liệu đến từ NIC), card mạng gửi yêu cầu ngắt (IRQ) đến CPU để xử lý. Nhưng vấn đề là Ubuntu mặc định chạy irqbalance.
- Mục đích của
irqbalancelà phân đều các IRQ ra nhiều CPU để tận dụng tài nguyên. - Nhưng trong hệ thống dual-socket, điều này khiến:
- IRQ từ card mạng ở socket A có thể được xử lý bởi CPU ở socket B.
- Điều này vô tình gây ra hiện tượng dữ liệu “đi vòng” → chậm.
Cách khắc phục là tắt irqbalance:
systemctl disable irqbalanceKích hoạt script Mellanox để tự động gán IRQ của card mạng về đúng socket chứa nó:
systemctl enable set_irq_affinity_bynodeĐiều này giúp card mạng Mellanox chỉ gửi IRQ đến CPU trên cùng socket → Xử lý nhanh, không cần đi qua QPI.
Hiệu quả đạt được
| Thành phần | Tối ưu hóa | Lợi ích |
|---|---|---|
| MTU | 9000+ | Giảm overhead, tăng throughput |
| Bonding + LACP | 802.3ad + layer3+4 | Tận dụng hết băng thông NIC |
| VLAN tách biệt | VLAN riêng cho backend | Không nhiễu với traffic client |
| irqbalance | Tắt + set IRQ theo NUMA | Giảm latency, tăng hiệu suất network |
6.6. Tối ưu TCP/IP Stack
Mục tiêu:
- Tăng hiệu suất mạng (đặc biệt trong môi trường 100Gbps).
- Tránh nghẽn socket TCP – tức là tránh tình trạng “nghẽn cổ chai” khi có quá nhiều dữ liệu.
- Giảm rủi ro mất kết nối khi số lượng kết nối hoặc lượng dữ liệu quá lớn.
Tối ưu buffer cho TCP socket
Linux có sẵn các giới hạn (khá nhỏ) về bộ nhớ dùng cho TCP socket. Điều này không phù hợp khi bạn chạy mạng 100GbE (100 Gigabit Ethernet).
Thông số chính:
| Thông số | Mô tả |
|---|---|
net.core.rmem_max | Kích thước buffer nhận tối đa mà một socket có thể dùng |
net.core.wmem_max | Kích thước buffer gửi tối đa mà một socket có thể dùng |
net.ipv4.tcp_rmem | Bộ nhớ cho TCP socket khi nhận dữ liệu (min, default, max) |
net.ipv4.tcp_wmem | Bộ nhớ cho TCP socket khi gửi dữ liệu (min, default, max) |
net.core.optmem_max | Dung lượng tối đa cho bộ nhớ phụ trợ của socket |
Giá trị khuyến nghị:
net.core.rmem_max = 4194304 # 4MB nhận tối đa
net.core.wmem_max = 4194304 # 4MB gửi tối đa
net.ipv4.tcp_rmem = 4096 87380 4194304
net.ipv4.tcp_wmem = 4096 65536 4194304
net.core.optmem_max = 4194304Lưu ý: các giá trị như 4096, 87380, 4194304 là byte.
Nói thêm về net.core.optmem_max thì đây là giới hạn cho dung lượng bộ nhớ phụ trợ mà mỗi socket có thể sử dụng được tính bằng byte. Nếu để quá nhỏ thì các socket có thể bị lỗi hoặc nghẽn nếu cần dùng metadata mà không đủ chỗ chứa. Trong môi trường băng thông tốc độ cao (như 100GbE), gói tin đến rất nhanh → metadata tăng lên nhiều → bộ nhớ phụ trợ cũng cần nới lên.
Giá trị khuyến nghị cho net.core.optmem_max là 4MB (4194304) cho hệ thống 100Gbps trở lên
Tác dụng thực tế:
- Tăng buffer = giảm packet bị drop → dữ liệu truyền ổn định hơn.
- Tối ưu băng thông TCP, giúp đạt gần mức tối đa của card mạng (100Gbps).
- Tránh các lỗi
connection reset,broken pipehoặc mất kết nối do socket bị nghẽn.
6.7. Tăng giới hạn theo dõi kết nối với nf_conntrack
NF_conntrack là gì?
nf_conntrack là hệ thống theo dõi trạng thái kết nối mạng trong Linux (thuộc Netfilter). Nó ghi nhớ các kết nối TCP, UDP, ICMP… đang hoạt động → giúp routing, firewall, NAT hoạt động chính xác.
Mỗi kết nối (client → Ceph OSD, hoặc giữa các OSD) sẽ chiếm 1 slot trong bảng này.
Tại sao phải chỉnh nó?
- Mặc định kernel chỉ cấp vài trăm nghìn slot (khoảng 100k – 300k).
- Trong các hệ thống lớn như Ceph có hàng ngàn OSD và client, tổng số kết nối có thể lên đến hàng triệu.
- Nếu đầy → Kết nối mới sẽ bị drop (mất), log báo lỗi
nf_conntrack: table full.
Trong dmesg sẽ thấy lỗi như:
nf_conntrack: table full, dropping packetGiải pháp cấu hình.
net.netfilter.nf_conntrack_max = 1524288
net.nf_conntrack_max = 1524288 # Cả 2 dòng để chắc chắnCon số này cho phép 1.5 triệu kết nối đồng thời, phù hợp với Ceph quy mô lớn.
Tối ưu hệ thống khác trong /etc/sysctl.conf
Dưới đây là các tham số thường dùng để xử lý tốt IO và TCP socket ở mức lớn:
| Thông số | Giải thích | Tác dụng |
|---|---|---|
vm.dirty_ratio = 80 | Cho phép tối đa 80% RAM chứa dữ liệu chưa ghi ra đĩa | Tăng buffer ghi → hiệu suất I/O cao hơn |
vm.dirty_background_ratio = 3 | Khi RAM chứa 3% dữ liệu dirty → ghi ra đĩa ở chế độ nền | Tránh ghi đột ngột, làm nghẽn |
net.core.netdev_max_backlog = 250000 | Số lượng gói tối đa xếp hàng khi chưa xử lý xong | Tránh mất gói khi xử lý mạng chậm |
net.ipv4.tcp_max_tw_buckets = 2000000 | Tối đa socket ở trạng thái TIME_WAIT | Hệ thống nhiều kết nối ngắn sống sót |
net.ipv4.tcp_tw_reuse = 1 | Cho phép tái sử dụng socket TIME_WAIT | Tiết kiệm tài nguyên, tăng tái sử dụng |
net.ipv4.tcp_fin_timeout = 10 | Giảm thời gian chờ đóng kết nối | Kết nối cũ đóng nhanh hơn |
net.core.somaxconn = 5000 | Tăng hàng đợi kết nối TCP (backlog queue) | Xử lý tốt nhiều client đồng thời |
Tác dụng tổng thể, giúp hệ thống:
- Xử lý hàng triệu kết nối TCP/UDP cùng lúc
- Không bị rớt gói, đơ mạng khi tải cao
- Ghi ra đĩa mượt hơn, giảm nguy cơ
flushbất ngờ
Đây là config /etc/sysctl.conf của mình, hãy tham khảo nó nhé.
# /etc/sysctl.conf
kernel.pid_max = 4194303
kernel.threads-max=2097152
vm.max_map_count=524288
vm.min_free_kbytes=2097152
vm.vfs_cache_pressure=10
vm.zone_reclaim_mode=0
vm.dirty_ratio=80
vm.dirty_background_ratio=3
net.ipv4.tcp_timestamps=0
net.ipv4.tcp_sack=1
net.core.netdev_max_backlog=250000
net.ipv4.tcp_max_syn_backlog=100000
net.ipv4.tcp_max_tw_buckets=2000000
net.ipv4.tcp_tw_reuse=1
net.core.rmem_max=4194304
net.core.wmem_max=4194304
net.core.rmem_default=4194304
net.core.wmem_default=4194304
net.core.optmem_max=4194304
net.ipv4.tcp_rmem=4096 87380 4194304
net.ipv4.tcp_wmem=4096 65536 4194304
net.ipv4.tcp_low_latency=1
net.ipv4.tcp_adv_win_scale=1
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save=1
net.ipv4.tcp_syncookies=0
net.core.somaxconn=5000
net.ipv4.tcp_ecn=0
net.ipv4.conf.all.send_redirects=0
net.ipv4.conf.all.accept_source_route=0
net.ipv4.icmp_echo_ignore_broadcasts=1
net.ipv4.tcp_no_metrics_save=1
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_fin_timeout=10
net.netfilter.nf_conntrack_max=1524288
net.nf_conntrack_max=15242886.8. Tối ưu RX/TX Buffers NIC (Layer-2)
- RX/TX buffer là bộ nhớ cache của phần cứng ở trong card mạng.
- Nếu quá nhỏ → mất gói → giảm tốc độ.
Ví dụ khi rót nước vào ly, hãy tưởng tượng:
- Nước = Dữ liệu mạng (packet).
- Vòi nước chảy rất nhanh = Mạng tốc độ cao (100Gbps).
- Ly nước = RX/TX buffer trong card mạng (NIC).
- Người uống nước = CPU (hoặc hệ điều hành) đang đọc dữ liệu đó.
Trường hợp ly quá nhỏ (buffer nhỏ):
- Bạn mở vòi nước tốc độ cao, nhưng ly nhỏ quá → tràn nước ra ngoài.
- Nước bị đổ ra ngoài = mất gói tin (packet drop).
- CPU chưa kịp uống thì nước đã tràn → hiệu suất giảm, nghẽn mạng.
Trường hợp ly đủ lớn (buffer lớn):
- Ly to hơn (tăng RX/TX buffer) → chứa được nhiều nước trong lúc chờ CPU đọc.
- CPU (người uống) có đủ thời gian xử lý từng ngụm nước.
- Không tràn, không mất dữ liệu → mạng mượt, đạt hiệu suất cao.
Vậy RX/TX Buffer là gì?
- RX buffer: nơi card mạng lưu tạm dữ liệu nhận được từ mạng trước khi gửi lên CPU.
- TX buffer: nơi card mạng chờ sẵn dữ liệu từ CPU để gửi ra mạng.
Cách tăng dung lượng buffer:
Bạn dùng lệnh ethtool để tăng kích thước:
ethtool -G ethX rx 8192 tx 8192Trong đó:
ethXlà tên card mạng (ví dụ:ens1f0hoặceth0)8192là số lượng buffer (slot) – càng lớn thì ly càng to.
| So sánh | Ly nhỏ (buffer thấp) | Ly lớn (buffer cao) |
|---|---|---|
| Vòi nước | 100GbE (gói đến rất nhanh) | 100GbE |
| Ly (buffer) | Nhỏ, tràn dễ | To, chứa tốt |
| Người uống (CPU) | Chưa kịp xử lý đã tràn | Có thời gian xử lý |
| Hệ quả | Mất gói, giảm throughput | Mạng ổn định, hiệu suất cao |
Một số NIC cho phép lên đến 16384 buffer, nhưng 8192 là giá trị ổn định, an toàn và đủ tốt trong hầu hết hệ thống 100GbE.
6.9. Multipath (đa đường kết nối đến ổ đĩa)
Trong hệ thống dùng disk enclosure (JBOD), mỗi ổ đĩa có thể thấy qua nhiều đường (multi-path).
Ví dụ vận chuyển hàng đến kho:
- Ổ đĩa = Kho hàng
- Máy chủ (server) = Xe tải đi lấy/ghi dữ liệu
- Đường đi (path) = Đường vật lý (cáp SAS hoặc HBA) từ server tới ổ đĩa
Trường hợp mặc định: Active/Standby (1 đường chính, 1 dự phòng)
- Xe tải chỉ chạy trên 1 đường chính
- Đường còn lại chỉ được dùng khi đường chính hỏng
- 👉 Chỉ dùng được 1 nửa băng thông, ví dụ: 6 GB/s (dù có 2 đường)
Trường hợp cấu hình: Active/Active (multipath hiệu quả)
- Xe tải chạy cùng lúc trên cả 2 đường
- Lưu lượng chia đều → tốc độ gấp đôi, ví dụ: 12 GB/s
🔌 Cấu hình đi dây phổ biến (Multipath)
Đây là sơ đồ mô tả một server + một box chứa ổ đĩa (JBOD).
+---------+ +--------------------+
| Server | | Disk Enclosure |
| | | (JBOD / Data60) |
| | | |
| [HBA1] |========| Port A |
| [HBA2] |========| Port B |
+---------+ +--------------------+- Server có 2 HBA card → gắn 2 sợi cáp SAS:
- Cả 2 sợi đều gắn vào cùng 1 box
- Mỗi cổng trên box là 1 SAS expander port (đường vào khác nhau)
- Cả 2 sợi đều gắn vào cùng 1 box
Trong hệ thống multipath, 2 sợi dây SAS thường gắn vào cùng 1 box (qua 2 port khác nhau),
Để tạo 2 đường vật lý đến cùng một tập ổ đĩa → tăng độ tin cậy và băng thông. Nhưng như vậy thì ổ đĩa trong box sẽ xuất hiện 2 lần trong hệ điều hành → bạn cần dùng multipath để hợp nhất.
Dưới đây là minh họa chi tiết hơn kết nối server với 1 box ổ đĩa (JBOD) qua 2 HBA và 2 dây SAS, tạo multipath:
+---------------------------+
| Server |
| |
| +--------+ +--------+ |
| | HBA #1 | | HBA #2 | |
| +--------+ +--------+ |
| | | |
+-------|-------------|-----+
| |
====== ====== (2 dây SAS)
| |
+----------------+-------------+----------------+
| |
| Disk Enclosure (JBOD/Box) |
| |
| +------------+ +------------+ |
| | Port A | | Port B | |
| +------------+ +------------+ |
| | | |
| [Expander] [Expander] |
| | | |
| +---+---+----------+-----+----+ |
| | sda sdb sdc ... sdz (HDDs) |
+------------------------------------------------+HBA #1, HBA #2: 2 card lưu trữ cắm vào PCIe trên server
2 dây SAS: gắn vào 2 port khác nhau trên cùng 1 box
Mỗi ổ đĩa trong box sẽ được nhìn thấy qua cả hai đường → ví dụ:
/dev/sdaa(qua HBA1)/dev/sdab(qua HBA2)
Cả hai đường đều dẫn tới cùng 1 ổ đĩa thật, nên bạn phải cấu hình multipath để hệ thống hợp nhất thành:
/dev/mapper/mpatha
⚠️ Vì sao cần điều chỉnh?
Mặc định của Ubuntu là failback thủ công + path selector không hiệu quả → hệ thống chỉ dùng 1 đường tại 1 thời điểm.
Bạn đang có 2 dây SAS → phải tận dụng cả 2 thì mới đạt 12 GB/s → nếu không sẽ bị giới hạn ở 6 GB/s.
# /etc/multipath.conf
defaults {
user_friendly_names yes
path_grouping_policy "group_by_prio"
path_selector "service-time 0"
failback immediate
path_checker tur
no_path_retry 5
retain_attached_hw_handler "yes"
rr_weight uniform
fast_io_fail_tmo 5
rr_min_io 1000
rr_min_io_rq 1
}Giải thích các thông số trong /etc/multipath.conf
| Tham số | Giải thích ngắn gọn |
|---|---|
path_selector "service-time 0" | Cân bằng theo thời gian đáp ứng I/O (latency) → dùng cả 2 đường hiệu quả |
failback immediate | Nếu đường chính bị mất rồi khôi phục → quay lại dùng ngay, không chờ |
path_grouping_policy "group_by_prio" | Nhóm theo độ ưu tiên, kết hợp tốt với active-active setup |
rr_weight uniform, rr_min_io | Round-robin đều đặn giữa các path → tránh dồn vào 1 đường duy nhất |
path_checker tur | Kiểm tra đường bằng Test Unit Ready – cơ bản và nhanh |
no_path_retry 5 | Thử lại 5 lần nếu một đường mất kết nối |
fast_io_fail_tmo 5 | Nếu mất I/O → timeout nhanh sau 5 giây, không treo lệnh ghi |
Blacklist thiết bị không cần multipath để tránh multipath nhận nhầm thiết bị không cần thiết (ví dụ: NVMe, RBD, iSCSI client…):
blacklist {
devnode "^nvme.*"
devnode "scini*"
devnode "^rbd[0-9]*"
devnode "^nbd[0-9]*"
}Bạn có thể kiểm tra trạng thái multipath hiện tại bằng lệnh:
multipath -llNếu thấy cả hai đường được đánh dấu active ready thì bạn đã cấu hình đúng.
6.10. Lọc LVM để tránh lỗi mount sai thiết bị
Đây là vấn đề nhận nhầm thiết bị, bạn hãy tưởng tượng hệ thống như sau:
Bạn có một ổ đĩa vật lý gắn qua 2 đường (multipath), mỗi đường sẽ thấy ổ đĩa này là một thiết bị riêng biệt /dev/sdaa, /dev/sdab (đường A và B) nhưng thật ra chúng đều là cùng 1 ổ đĩa!
Như vậy nếu không cẩn thận, hệ thống có thể dùng nhầm thiết bị đơn (/dev/sdaa) thay vì thiết bị được hợp nhất (/dev/mapper/mpathaa). Điều này cực kỳ nguy hiểm vì nó bỏ qua cơ chế failover của multipath và nếu đường /dev/sdaa bị lỗi, dữ liệu mất kết nối ngay dù còn đường dự phòng.
Giải pháp là lọc thiết bị LVM trong /etc/lvm/lvm.conf, ta dùng filter để:
- Chỉ cho phép các thiết bị đáng tin cậy được LVM nhận diện và thao tác (scan, vgchange, mount…).
- Loại bỏ các thiết bị đơn lẻ, không qua multipath.
devices {
filter = [
"a|/dev/sd.*[1-9]$|", # cho phép sdX1, sdX2... (chỉ phân vùng, không phải ổ đĩa gốc)
"a|/dev/mapper/mpath*|", # cho phép multipath
"a|/dev/nvme[0-9]n*|", # cho phép NVMe
"r|.*|" # từ chối mọi thứ còn lại
]
}Tác dụng của config trên sẽ làm cho LVM chỉ làm việc với thiết bị qua multipath hoặc NVMe.
Tác dụng của regex dòng filter:
| Biểu thức | Nghĩa |
|---|---|
| `”a | /dev/sd.*[1-9]$ |
| `”a | /dev/mapper/mpath* |
| `”a | /dev/nvme[0-9]n* |
| `”r | .* |
Nếu không cấu hình filter thì sao?
LVM có thể tạo volume group (VG) trên ổ đĩa đơn (/dev/sdaa) làm cho khi reboot, multipath có thể đổi tên thiết bị → hệ thống mount nhầm, gây lỗi:
- device not found
- mất dữ liệu
- mất failover multipath
Tác dụng cuối cùng
| Lợi ích | Mô tả |
|---|---|
| An toàn thiết bị | Tránh thao tác trực tiếp lên đường đơn của ổ đĩa multipath |
| Ổn định cấu hình LVM | Luôn mount đúng thiết bị multipath |
| Dễ quản lý, dễ backup | LVM chỉ làm việc với thiết bị chuẩn hóa (/dev/mapper/*) |
7. Swapfile lớn để chống OOM (Out-of-Memory)
Tình huống thiếu RAM hoặc RAM đầy = OOM killer xuất hiện do các thành phần như OSD, MDS, MON trong Ceph có thể tiêu tốn nhiều RAM, nhất là khi:
- Có nhiều ổ (OSD)
- Nhiều client truy cập
- Dữ liệu metadata phức tạp (CephFS, MDS)
Nếu hệ thống hết sạch RAM, Linux sẽ kích hoạt cơ chế gọi là OOM killer (Out-Of-Memory Killer). Đây là một cơ chế tự động giết bớt process để giải phóng RAM.
Nhưng với Ceph nếu OSD hoặc MDS bị OOM kill → cluster báo lỗi, mất dữ liệu tạm thời, hoặc gây “degraded”, peering lại, thậm chí “full cluster”.
Giải pháp của tôi là tăng swap lên ~200GB. Vậy Swap là gì?
- Nó là bộ nhớ ảo (thường nằm trên đĩa) được sử dụng khi RAM đầy.
- Không nhanh bằng RAM, nhưng giúp “câu giờ”, ngăn OOM xảy ra ngay.
| Tác dụng | Giải thích đơn giản |
|---|---|
| Ngăn process bị giết đột ngột | Có thêm chỗ chứa khi RAM đầy |
| Ổn định Ceph khi có peak load | Khi RAM bị “burst” đột ngột, OSD/MDS vẫn sống |
| Giảm rủi ro mất dữ liệu tạm thời | Ceph không mất OSD/MDS khi RAM cạn |
Vậy có nhược điểm gì không?
| Nhược điểm | Có ảnh hưởng? |
|---|---|
| Swap chậm hơn RAM | ✅ Nhưng vẫn tốt hơn là mất process |
| Có thể gây I/O load | ✅ Nhưng trên SSD/NVMe tốc độ cao thì ảnh hưởng ít |
| Chiếm ổ đĩa | ✅ Nhưng 200GB là rẻ so với RAM/server Ceph |
Cách tạo swap 200GB (nếu cần):
fallocate -l 200G /swapfile
chmod 600 /swapfile
mkswap /swapfile
swapon /swapfileVà thêm vào /etc/fstab:
/swapfile none swap sw 0 0Kết luận.
Việc tăng dung lượng swap mà không dùng đến thì về cơ bản không gây hại, không làm chậm hệ thống, và có thể coi là “bảo hiểm” cho RAM — miễn là bạn còn dư ổ cứng, vì:
- Swap chỉ được sử dụng khi RAM gần đầy.
- Nếu RAM vẫn còn nhiều, Linux sẽ không động tới swap, vì RAM nhanh hơn.
- Tức là: “có thì để đó, khi nào cần thì xài”.
Khuyến nghị cấu hình thêm giảm swappiness.
Swappiness là thông số kernel quyết định khi nào hệ thống sẽ bắt đầu dùng swap.
- Mặc định là 60 → Linux sẽ bắt đầu dùng swap khi RAM chỉ mới dùng một phần.
- Đặt về
1nghĩa là: chỉ khi RAM sắp đầy mới dùng swap. - Cấu hình trong
/etc/sysctl.conf:
vm.swappiness = 1Bảng giá trị swappiness.
| Giá trị swappiness | Ý nghĩa |
|---|---|
0 | Chỉ dùng swap khi RAM thật sự đầy. Cực kỳ ưu tiên dùng RAM |
60 | Mức cân bằng. Nếu RAM dùng ~40%–60% thì hệ thống đã bắt đầu swap |
100 | Dùng swap rất tích cực. Hệ thống sẽ đẩy bớt dữ liệu RAM sang swap ngay cả khi RAM còn trống |
Chốt hạ thế này.
| Tình huống | Có nên tăng swap? | Giải thích nhanh |
|---|---|---|
| RAM nhiều, ổ đĩa dư | ✅ Có thể tăng | Là “bảo hiểm”, không ảnh hưởng |
| RAM hạn chế, workload không ổn định | ✅ Nên tăng | Tránh OOM, tăng tính ổn định |
| Swap nằm trên SSD/NVMe | ✅ Tốt hơn nhiều | Ít ảnh hưởng đến hiệu năng |
| Swap trên HDD | ⚠️ Dùng tạm thôi | Không nên dựa vào swap lâu dài |
8. Cấu hình Erasure Coding (EC)
Erasure Coding (EC) là gì?
Erasure Coding (EC) là cơ chế chống mất dữ liệu thay cho kiểu replica 3x (mỗi dữ liệu có 3 bản sao).
Dữ liệu được chia thành nhiều phần nhỏ (chunks) và thêm vào các phần kiểm lỗi (parity chunks).
Khi cần phục hồi, chỉ cần đủ số data chunk là có thể tái tạo lại dữ liệu gốc, ngay cả khi có vài chunk bị mất.
Cấu hình EC trong cụm Ceph này là EC 10+4
| Thành phần | Số lượng |
|---|---|
| Data chunk | 10 |
| Parity chunk | 4 |
| Tổng cộng | 14 chunks (mỗi object lưu trên 14 OSDs) |
- Lợi ích là chịu được mất cùng lúc 4 chunk (do mất OSD, host, v.v…)
- Tốn ít dung lượng hơn replica 3x: 10+4 = 1.4x overhead, trong khi replica 3x là 3.0x.
Crush Failure Domain = host
Nghĩa là mỗi chunk sẽ được đặt trên 1 máy chủ (host) khác nhau.
- Nếu một host chết, Ceph vẫn còn đủ chunk trên các host khác để khôi phục dữ liệu:
- An toàn khi 1 server hỏng
- Hiệu quả phân bố dữ liệu
- Dễ kiểm soát với 4 host/rack × 10 rack = 40 host nên dùng failure domain = host là hợp lý hơn.
- Và chọn 10+4 là chính xác, vì vừa đủ an toàn (mất 1 rack vẫn sống), vừa khả thi trên hạ tầng thật
Mình sẽ vẽ sơ đồ đơn giản để bạn hình dung rõ hơn về cấu hình Erasure Coding 10+4 với failure domain = host, và tại sao mất 1 rack vẫn an toàn.
Mục tiêu:
- 10 data chunks + 4 parity chunks = 14 chunk tổng cộng
- Mỗi chunk nằm trên 1 host khác nhau
- Mỗi rack có 4 host, có 10 rack → 40 host
Sơ đồ 10 rack × 4 host = 40 host
Mỗi ký hiệu D1 đến D10 là data chunkP1 đến P4 là parity chunk
Mỗi hàng = 1 rack
Mỗi cột = 1 host trong rack
Rack 1: [D1] [ ] [ ] [ ]
Rack 2: [D2] [ ] [ ] [ ]
Rack 3: [D3] [ ] [ ] [ ]
Rack 4: [D4] [ ] [ ] [ ]
Rack 5: [D5] [ ] [ ] [ ]
Rack 6: [D6] [ ] [ ] [ ]
Rack 7: [D7] [ ] [ ] [ ]
Rack 8: [D8] [ ] [ ] [ ]
Rack 9: [D9] [ ] [ ] [ ]
Rack10: [D10][P1][P2][P3]Mỗi chunk nằm ở một host khác nhau, không có 2 chunk nào trong cùng 1 host hoặc cùng 1 rack (nếu được cấu hình kỹ hơn)
Tình huống mất 1 rack hoàn toàn (ví dụ: Rack 10)
Rack10: [X] [X] [X] [X] ← ❌ mất toàn bộ rackLúc này hệ thống mất D10, P1, P2, P3 → mất 4 chunk
Vẫn còn:
D1→D9(9 data chunks)P4(1 parity chunk)
Tổng còn lại: 10 chunks → đủ để khôi phục dữ liệu gốc
Vì sao vẫn an toàn?
Cấu hình 10+4 → chịu được mất tối đa 4 chunk
Mỗi chunk nằm ở host khác nhau → nếu rack chỉ có 4 host → mất 1 rack = mất 4 chunk
Vẫn đủ để đọc/ghi dữ liệu bình thường
Kết luận trực quan
| Mất bao nhiêu rack? | Số chunk mất | Dữ liệu còn khôi phục được? |
|---|---|---|
| 0 | 0 | ✅ Rõ ràng rồi |
| 1 | 4 (1 chunk/host × 4 host) | ✅ OK – đúng mức chịu lỗi |
| 2 | 8 | ❌ Quá số lượng parity (4) |
🚫 Tại sao KHÔNG dùng 7+3 với domain = rack?
Ý định ban đầu của mình là dùng 7 data + 3 parity (10 chunk), mỗi chunk nằm ở 1 rack khác nhau (domain = rack) → giúp chống mất cả rack
❌ Nhưng lỗi xảy ra:
- Khi deploy thật, 1 OSD bị stale (nghĩa là mất kết nối lâu, không đồng bộ).
- Vì crush rule yêu cầu mỗi chunk phải nằm ở rack khác nhau, nên nếu thiếu 1 rack hoặc OSD trong rack đó → Ceph không đủ nơi để đặt chunk làm cho Ceph không thể ghi hoặc tái tạo dữ liệu, gây mất cân bằng hoặc lỗi I/O
Lý do chính là trong cụm này mỗi rack chỉ có 4 host → cấu trúc không đủ linh hoạt để đảm bảo 10 chunk luôn nằm ở 10 rack.
📌 Một vài điểm kỹ thuật khác:
| Thành phần | Chi tiết |
|---|---|
| Ceph phiên bản | Reef 18.2.7 |
| MDS (Metadata Server) | Dùng 1 active MDS vì khi dùng nhiều MDS, rsync bị treo (CephFS bug) |
| Memory target cho OSD | Giữ mặc định 4MB – không thay đổi |
| Scrubbing | Cũng giữ mặc định – không cấu hình riêng |
Kết luận
| Lựa chọn | Ưu điểm | Nhược điểm/Giới hạn |
|---|---|---|
| 10+4, domain=host | An toàn nếu mất 1–4 host, tối ưu dung lượng | Cần 14 OSDs hoạt động để ghi |
| 7+3, domain=rack | Tốt về mặt lý thuyết (chống mất cả rack) | Không khả thi nếu thiếu rack/host |
Tính toán xác suất lỗi ổ cứng sử dụng phân phối Poisson.
- Vấn đề đặt ra bạn có 2400 ổ cứng, và muốn biết:
- Mỗi ngày có bao nhiêu ổ cứng có thể bị hỏng?
- Và xác suất bao nhiêu ổ cùng hỏng trong 1 ngày là bao nhiêu?
- Mỗi ngày có bao nhiêu ổ cứng có thể bị hỏng?
Mô hình hóa bằng phân phối Poisson
Poisson là phân phối dùng để tính xác suất xảy ra của các sự kiện hiếm, xảy ra độc lập (ví dụ: ổ cứng hỏng, tai nạn, lỗi mạng…).
Trong trường hợp này, mỗi ổ cứng có xác suất bị hỏng trong 1 ngày là rất nhỏ (rất hiếm) → dùng Poisson là hợp lý.
| Thông số | Giá trị |
|---|---|
| Xác suất 1 ổ hỏng/ngày | p = 10⁻⁵ (rất nhỏ) |
| Số lượng ổ cứng | N = 2400 |
| Kỳ vọng trung bình λ | λ = N × p = 2400 × 10⁻⁵ = 0.024 |
Sử dụng công thức phân phối Poisson tính xác suất xảy ra lỗi:
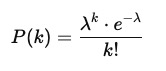
Trong đó:
λlà trung bình số lỗi/ngàyklà số lỗi cụ thể bạn muốn tínhelà hằng số Euler ≈ 2.718
Tính kết quả cụ thể
| Số ổ hỏng (k) | P(k) ≈ | Diễn giải |
|---|---|---|
k = 1 | ≈ 0.023 | Mỗi ~43 ngày thì có 1 ổ hỏng |
k = 2 | ≈ 0.0002 | 2 ổ hỏng cùng ngày xảy ra ~mỗi 13 năm |
k = 3+ | ≈ gần như 0 | Xác suất cực nhỏ, hầu như không xảy ra |
Kết luận.
- Trong một hệ thống 2400 ổ cứng:
- Trung bình mỗi 40–45 ngày mới có 1 ổ bị hỏng
- 2 ổ hỏng cùng lúc → hiếm gặp (5–10 năm mới xảy ra)
- Do đó, dùng Erasure Coding 10+4 là đủ an toàn, vì bạn có thể chịu được 4 ổ mất đồng thời
Metadata pool được cấu hình replication 5x
- Không dùng erasure coding cho metadata vì:
- Metadata cần phản hồi nhanh, dung lượng nhỏ.
- Dùng replication (5 bản sao) sẽ an toàn và hiệu quả hơn.
9. OSD memory target = 4MB (mặc định)
Tham số osd_memory_target là gì?
Là giới hạn bộ nhớ đệm (cache) mà mỗi OSD daemon (quá trình Ceph OSD) được phép dùng.
Khi bộ nhớ dùng vượt quá giá trị này, Ceph sẽ bắt đầu cắt giảm cache → giải phóng RAM.
Nó chủ yếu ảnh hưởng đến BlueStore cache – nơi OSD lưu tạm metadata, journal, key-value rocksdb…
Mặc định là 4MB – có vẻ thấp, nhưng…
- Đó là mặc định nội bộ cho một vùng cache cụ thể (cache trim trigger), chứ không phải tổng RAM của OSD.
- Thực tế, một OSD vẫn có thể dùng vài trăm MB đến hàng GB RAM, tùy số lượng PG, IOPS và loại backend.
Khi nào tham số này có tác dụng?
Nếu bạn giới hạn RAM máy chủ (ví dụ chỉ có 32GB, nhiều OSD), bạn muốn kiểm soát lượng RAM dùng cho cache.
Nếu để quá lớn, Ceph sẽ chiếm RAM quá đà, có thể gây OOM.
Có nên thay đổi không?
| Tình huống | Có nên thay đổi? | Gợi ý |
|---|---|---|
| Máy chủ có RAM thấp (<64GB) | ✅ Có thể giảm | Đặt nhỏ hơn để tránh OOM |
| Máy chủ RAM cao, ổ SSD/NVMe nhanh | ⚠️ Có thể tăng | Đặt ~1–4GB để tận dụng cache |
| Cụm ổ cứng nhiều, OSD load cao | ✅ Xem xét tăng | Giúp giảm I/O thực sự |
Bạn có thể chỉnh trong file config Ceph (ceph.conf):
[osd]
osd_memory_target = 4294967296 # = 4GBHoặc apply dynamic qua ceph config set:
ceph config set osd osd_memory_target 4294967296Như vậy mặc định 4MB là mức khởi đầu nhỏ để tránh tiêu tốn RAM không cần thiết. Với hệ thống như của mình đang có nhiều RAM, OSD mạnh, nên mình giữ mặc định vì chưa thấy dấu hiệu thiếu RAM hoặc cache quá nóng.
Nhưng nếu hệ thống của các bạn có nhiều IOPS hoặc muốn tăng hiệu suất BlueStore, các bạn có thể tăng lên vài trăm MB hoặc vài GB.
Lưu ý rằng RAM của tham số osd_memory_target khác với RAM tổng thể dành cho mỗi OSD nhé. Đây là bảng so sánh để phân biệt chúng.
| Khái niệm | RAM “dành cho mỗi OSD” | osd_memory_target |
|---|---|---|
| Là cái gì? | Tổng RAM mà 1 OSD tiêu thụ | Giới hạn cache nội bộ |
| Do ai tính? | Người quản trị hệ thống | Kernel/Ceph tính |
| Thường là bao nhiêu? | 2–4GB (tùy HDD/SSD, PG…) | 4MB mặc định (có thể tăng) |
| Có thể thay đổi được không? | Không rõ ràng, là khuyến nghị | Có, cấu hình được |
| Chiếm bao nhiêu % RAM OSD? | 100% | ~10–30% nếu cấu hình lớn |
Giả sử bạn có 1 máy với 128GB RAM và 16 OSDs HDD, bạn nên dự trù 2GB RAM/OSD × 16 = 32GB. Và osd_memory_target sẽ đặt khoảng 512MB – 1GB, tùy ổ SSD hay HDD
ceph config set osd osd_memory_target 536870912 # 512MBTùy theo RAM/node và số OSD/node, bạn có thể chọn mức an toàn:
| RAM/node | Số OSD/node | Gợi ý osd_memory_target |
|---|---|---|
| 32GB | 8 | 512MB – 1GB |
| 64GB | 8–12 | 1GB – 2GB |
| 128GB+ | 16–24 | 2GB – 4GB |
osd_memory_target x số OSD < 70–80% RAM hệ thốngKết luận.
RAM dành cho mỗi OSD là khuyến nghị tổng thể để bạn phân bổ tài nguyên RAM hợp lý còn RAM dành cho osd_memory_target là 1 phần nhỏ bên trong, dùng để giới hạn cache BlueStore – bạn có thể và nên điều chỉnh nó khi có dư RAM
10. Ubuntu thay CentOS
IBM tuyên bố dừng CentOS 8 → mình chuyển sang Ubuntu 22.04.
11. Một số lưu ý.
Việc nghẽn cổ chai thực sự không phải CPU, PCIe hay Network mà là cách Ceph ghi dữ liệu.
🎯 Tốc độ mạng thì sao?
- Mỗi server có 2 card mạng 100Gbps, tổng lý thuyết là 200Gbps, tương đương 25GB/s.
- Tuy nhiên, vì chia sẻ giữa 2 mạng (public + cluster), thực tế xử lý được ~12GB/s cho lưu lượng Ceph.
=> Mạng KHÔNG phải là giới hạn.
🎯 Thế còn tốc độ đọc/ghi ổ cứng thì sao?
- Ổ cứng cơ HDD đọc/ghi tuần tự (sequential) rất nhanh, đạt ~250MB/s mỗi ổ.
- Nhưng Ceph không ghi theo kiểu tuần tự, nên đây là điểm mấu chốt.
🎯 Ceph và cách ghi dữ liệu.
Mặc định trong Ceph.
- Dữ liệu người dùng được chia thành object – mặc định mỗi object là 4MB.
- Nếu bạn dùng erasure coding kiểu 10+4, Ceph sẽ:
- Chia 4MB thành 10 phần data (400KB mỗi phần)
- Thêm 4 phần parity
- Tổng cộng ghi 14 phần (400KB/OSD) → trên 14 OSD khác nhau.
Vấn đề:
- 400KB là kích thước rất nhỏ đối với ổ HDD cơ học.
- Ổ cứng HDD có thời gian seek trung bình ~4ms (để đầu đọc đến đúng vị trí trên đĩa).
- Khi ghi từng khối 400KB ngẫu nhiên, tốc độ sẽ giảm mạnh.
(Seek là quá trình đầu đọc di chuyển đến đúng vị trí vật lý trên đĩa để đọc hoặc ghi dữ liệu)
Tính toán:
Nếu mỗi lần seek + ghi mất 4ms:
→ 1 giây ghi được 250 lần → 250 × 400KB = 100MB/s
➡ Thấp hơn nhiều so với 250MB/s nếu ghi tuần tự.
🎯 Kiểm chứng bằng iostat

- Lệnh
iostat -xk 1cho thấy cột cuối (%util) luôn gần 100%. - Điều này nghĩa là HDD luôn bận, chờ seek + ghi → I/O bị nghẽn tại tầng đĩa.
🎯 Giải pháp:
- Tăng kích thước objecttừ từ 4MB → 16MB.
- Khi đó:
- Mỗi chunk của 10+4 erasure code sẽ là 1.6MB thay vì 400KB,
- Ít seek hơn, hiệu suất mỗi lần ghi cao hơn.
🎯 Kết quả throughput tăng ~1.5 lần.
| Thành phần | Trước | Sau khi tối ưu |
|---|---|---|
| Object size | 4MB | 16MB |
| Chunk size (10+4) | 400KB | 1.6MB |
| Seek per object write | 14 lần seek nhỏ | 14 lần seek lớn hơn |
| Tổng throughput | 100MB/s/ổ | ~150MB/s/ổ |
Bài học rút ra trong hệ thống lưu trữ dùng ổ HDD + erasure coding, yếu tố quan trọng nhất ảnh hưởng đến hiệu suất không phải là tốc độ lý thuyết của thiết bị, mà là I/O pattern. I/O pattern chính là cách mà ứng dụng hoặc hệ thống đọc/ghi dữ liệu xuống thiết bị lưu trữ, có 2 loại đó là Tuần tự (Sequential) và ngẫu nhiên (Random).
| Kiểu I/O | Mô tả | Ví dụ thực tế |
|---|---|---|
| Tuần tự (Sequential) | Dữ liệu được ghi hoặc đọc liên tục, vị trí kế tiếp nhau | Ghi video, copy file lớn, backup |
| Ngẫu nhiên (Random) | Dữ liệu được ghi/đọc tại nhiều vị trí rải rác, không liền kề | Truy xuất database, ghi log nhỏ, Ceph EC |
11. So sánh Replication vs Erasure Coding
| Tiêu chí | Replication (3x) | Erasure Coding (10+4) |
|---|---|---|
| Tỉ lệ dùng đĩa | 33% | 71% |
| Hiệu suất ghi | Cao hơn | Thấp hơn |
| Độ phức tạp | Thấp | Cao |
| Dung lượng cần | Cao hơn | Tiết kiệm |
| Độ bền dữ liệu | Tốt | Tốt (nếu cấu hình đúng) |
12. Ưu điểm và nhược điểm của hệ thống
Ưu điểm
✅ Dung lượng lưu trữ lớn (20PiB)
✅ Throughput cực cao (~100GB/s)
✅ Tích hợp sâu với Kubernetes
✅ Kiến trúc mạng & lưu trữ tối ưu cho phân tán
✅ Fault-tolerant tới cấp rack
✅ Tối ưu CPU, IO và network stack triệt để
Nhược điểm
❌ Cấu hình ban đầu phức tạp.
❌ Erasure coding gây giảm hiệu suất ghi random.
❌ Đòi hỏi phần cứng cao cấp (CPU, NIC, SSD…)
❌ Cần chỉnh nhiều config kernel, sysctl, network…
❌ Một số bug tồn tại trong phiên bản Ceph mới (đa MDS)
13. Lời khuyên khi triển khai hệ thống Ceph lớn
- Tính toán kỹ object size và chunk size phù hợp với workload.
- Đầu tư phần cứng cân bằng: CPU mạnh, RAM đủ, NIC nhanh.
- Sử dụng Jumbo Frames nếu switch & card hỗ trợ.
- Tối ưu IRQ/Numa để tránh tắc nghẽn PCIe ↔ CPU.
- Triển khai monitoring & alerting từ đầu.
- Test từng thành phần (CPU load, disk IO, netperf) trước khi production.
14. Kết luận
Ceph là một lựa chọn mạnh mẽ cho các hệ thống lưu trữ phân tán với nhu cầu lớn về throughput và dung lượng. Tuy nhiên, để đạt hiệu suất tối đa như ví dụ 20PiB/100GB/s này, cần đầu tư rất nhiều vào phần cứng, kiến trúc mạng và tối ưu hệ thống ở mọi cấp độ.
Bài học quan trọng nhất là: hiểu rõ workload của mình trước khi thiết kế hệ thống và đừng ngại đầu tư thời gian vào việc trải nghiệm ở môi trường lab.
Hy vọng bài viết này sẽ hữu ích cho các bạn đang tìm hiểu hoặc chuẩn bị triển khai cluster Ceph ở quy mô lớn.
